
Object-oriented programming (OOP) is a design pattern that structures software development around objects, rather than functions and logic. A data unit containing distinct properties and behavior is referred to as an object.
The object-oriented programming (OOP) approach focuses mostly on objects that developers wish to handle rather than the logic necessary to do so. This programming approach is ideal for big, sophisticated, and frequently maintained applications. This includes software for design and production, but also extends to mobile applications.
Get hands-on with OOPs Foundations. Learn how to apply OOPs concepts in real-world scenarios.
Structure of object-oriented programming
The structure of object-oriented programming is divided into multiple building blocks as follows:
- Classes
- Objects
- Methods
- Attributes

Classes
A class is a flexible program-code template for constructing objects in object-oriented programming, containing initial values for state (member variables) and behavior implementations (member functions or methods).
Consider a real-world analogy of the same: A "Person" can be considered as a real-life example of a class that contains certain properties including name, age, and gender. A "Person" can thus be considered as a template from which different unique individuals can be created/derived.
Objects
An object is an instance of a class. It is a software "packet" that consists of a set of variables that define the object's possible states and a set of functions that define the object's behavior. Software objects are frequently used to model real-world items seen in daily life.
Citing the above example of a "Person" class, we can consider a random real-life individual (for example Elon Musk). Now Elon Musk can be considered as an object of the template class "Person" in the sense that he has a unique name, a well-defined age, and gender. There can be a lot more properties to differentiate one individual from another but this is just to convey the idea of an object in the real world.
Methods
A method is also known as a procedure in object-oriented programming (OOP).

A method accepts certain parameters as arguments, manipulates them, and generates an output when the method is invoked on an object. It basically manipulates the behavior of an object which is associated with a class.
Consider the above example of Elon Musk. Some of the methods associated with him include eating (eat()), sleeping(sleep()) and studying(study()).
Attributes
Classes and objects in object-oriented programming (OOP) contain attributes. In a nutshell, attributes are data structures that contain information and express a singular property about an object of that class.
The 4 pillars of Object-Oriented Programming
Encapsulation
The process of encapsulating data and the functions that deal with it in the same place is known as encapsulation. It's not always apparent which functions work on which variables when dealing with procedural languages, but object-oriented programming provides a structure for integrating data and associated processes into a single object.

Abstraction
Data abstraction is described as displaying only necessary information to the outside world while concealing background details, i.e., representing required information in a system without revealing specific details.
For example, a database system hides some aspects of data storage, creation, and maintenance. C++ classes also provide a large number of standard methods for the users while concealing the internal implementation details about these methods.
Inheritance
Inheritance is an object-oriented mechanism that allows one class to inherit the properties of another class. The derived class (also known as the child class) inherits the attributes and methods of the parent class (also known as the super class).

Polymorphism
Polymorphism is the flexibility to employ an operator or function in several ways or to give the operators or functions alternative meanings or functions. Polymorphism refers to a single function or operator that can function in a variety of ways depending on the context.

Definition of abstraction in c++
In C++, data abstraction is one of the most significant and crucial features of object-oriented programming. The process of exposing just only the necessary details to an average user while simultaneously concealing the nitty-gritty of actual code-based implementation is referred to as abstraction.
Consider the case of a person at the wheel of a car. The person knows that the accelerator pedal will increase the car's speed and that applying the brakes will decelerate it. He has no idea how the speed is increased by pressing the accelerator or how the accelerator and other controls are implemented inside the car. This is the definition of abstraction.
Data abstraction is commonly achieved in the following two ways:
1. Abstraction using classes
Classes can be used to accomplish abstraction. Using access specifiers, a class exposes only the data members and member functions that the external users of the class need to access/understand. The implementation details of the functions and other internally used member functions are hidden from the users.
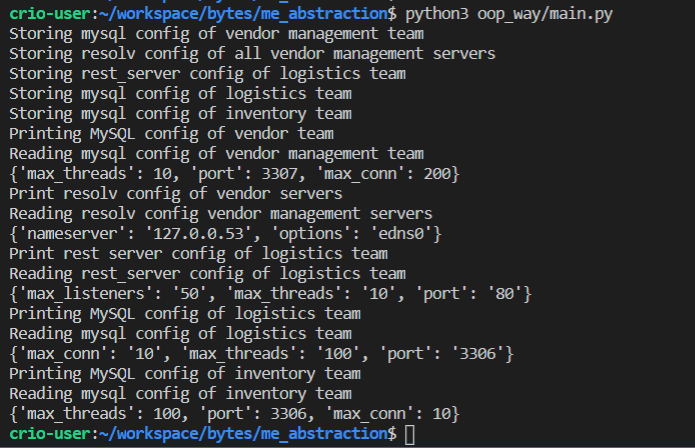
Here's a simple example to understand more about abstraction using classes.

Output:

In the above example, abstraction is implemented using classes. A class 'Product' contains three private members, a, b, c, that are only accessible by the member functions (here, pro() function) of the class 'Product'.
2. Abstraction using header files.
A header file is another sort of abstraction. The pow() function, for example, can be used to determine the power of an integer without knowing which algorithm function is used to do so. As a result, you can claim that header files shield the user from all implementation details.
Here's a simple example in C++ to understand more about abstraction using header files.

Output:

In the above example, a 'vector' header file is used to implement vectors in C++. Vector is a container used to store elements of similar data types in C++.
Here, the vector container is defined under the vector header file which hides implementation details of the container from the user.
Abstraction is enabled by access specifiers
In C++, access specifiers provide the foundation for implementing abstraction. Access specifiers can be used to impose limits on class members. For example:
Public access specifier
When class members are declared as public, the members can be accessed anywhere from the program.
Private access specifier
When the class members are declared as private, members can only be accessed by the member functions of the class.
What is an Abstract Class?
An abstract class is employed to supply an appropriate base class from which further classes are often derived. Abstract classes are solely used as a user interface and cannot be utilized to create objects. A compilation error occurs when an object of an abstract class is attempted to be instantiated.
Abstract classes are used to implement data abstraction in C++.
Why do we need abstraction?
Data abstraction is a programming (and design) method that separates the interface from the implementation.
Take, for example, an ATM. You can deposit money into your account, carry out transactions, withdraw cash, and do many other actions as such. But the question is, do you know how this ATM facilitates transactions and user actions in the background? The answer is, you don't. Because you don't need to.
You can say that an ATM clearly separates its internal implementation from its external interface, allowing us to interact with our bank accounts without knowing anything about its internals.
Classes in C++ enable a high level of data abstraction. They expose enough public methods to the outside world to allow them to experiment with the object's functionality and change object data, i.e. state, without having to know how the class is built inside.
The application, for example, can call the sort() method without knowing what algorithm the function uses to sort the input data. In reality, the actual implementation of the sorting feature may change between library releases, but your function call will work as long as the interface remains the same.
Design Strategy for Abstraction
Abstraction divides code into two categories: interface and implementation. So, while designing your component, keep the interface isolated from the implementation so that the interface remains unchanged if and when the underlying implementation changes.
In this situation, any applications that use these interfaces would remain unaffected and would only require recompilation with the most recent implementation.
Test your understanding
Here are a few curated problems to wrack your brain in data abstraction. Do give them a try and share your answers in the comments below.
Q1. From the options below, pick the abstract data type.
a) Int
b) Double
c) Class
d) String
Q2. The higher the degree of abstraction, the higher are the background details displayed to the user.
a) True
b) False
Advantages of Data Abstraction in OOP
1. Inadvertent user-level mistakes that might damage the object's state are shielded from class internals by abstraction.
2. It is possible to alter the internal implementation of a class without impacting the user, using data abstraction.
3. Only necessary details are presented to the user, which helps to enhance the security of an application or software.
The class author is allowed to make modifications to the data by defining data members exclusively in the private section of the class. If the implementation changes, all that is required is a review of the class code to determine the impact of the change.
Conclusion
By now it's apparent how useful data abstraction is in the real world. Data abstraction literally eliminates the complexity of background implementation for an average consumer thereby drawing a distinct line between development and usability. There's so much more to abstraction but this blog should be good enough to build a strong foundation for yourself in C++
Hope you enjoyed reading and learned more about abstraction in C++. If you think we missed out on covering something important, share your suggestions in the comments.
Happy Coding.
Further learning









