
In this age of modern technology, no one likes to wait for a long time for their search results or Twitter feeds to show up. Similarly, if you’re playing a game you would want to view the leaderboard updated in real-time. All these needs require a solution that is highly performant and rapid, which helps us in accessing data faster. Redis is a solution that makes all of this possible.
What is Redis?
Redis actually stands for Remote Dictionary Server.
It is basically a data-structure store that stores the data in the primary memory of a computer system. It uses key-value pairs to store the data, which is just like a HashMap in Java, a dictionary in Python, or an object in JavaScript. This is also why it is sometimes referred to as a NoSQL database.
Redis is an open-source project with a flourishing community.
Features of Redis
In-memory storage
Well, conventionally all the databases store and access the data from hard disks and SSDs, which are secondary memory. As we all know, primary memory is faster than secondary memory, as it can be accessed directly by the processor.
Now, since Redis stores its data on the primary memory, reading and writing are made faster than databases that store data on disks.
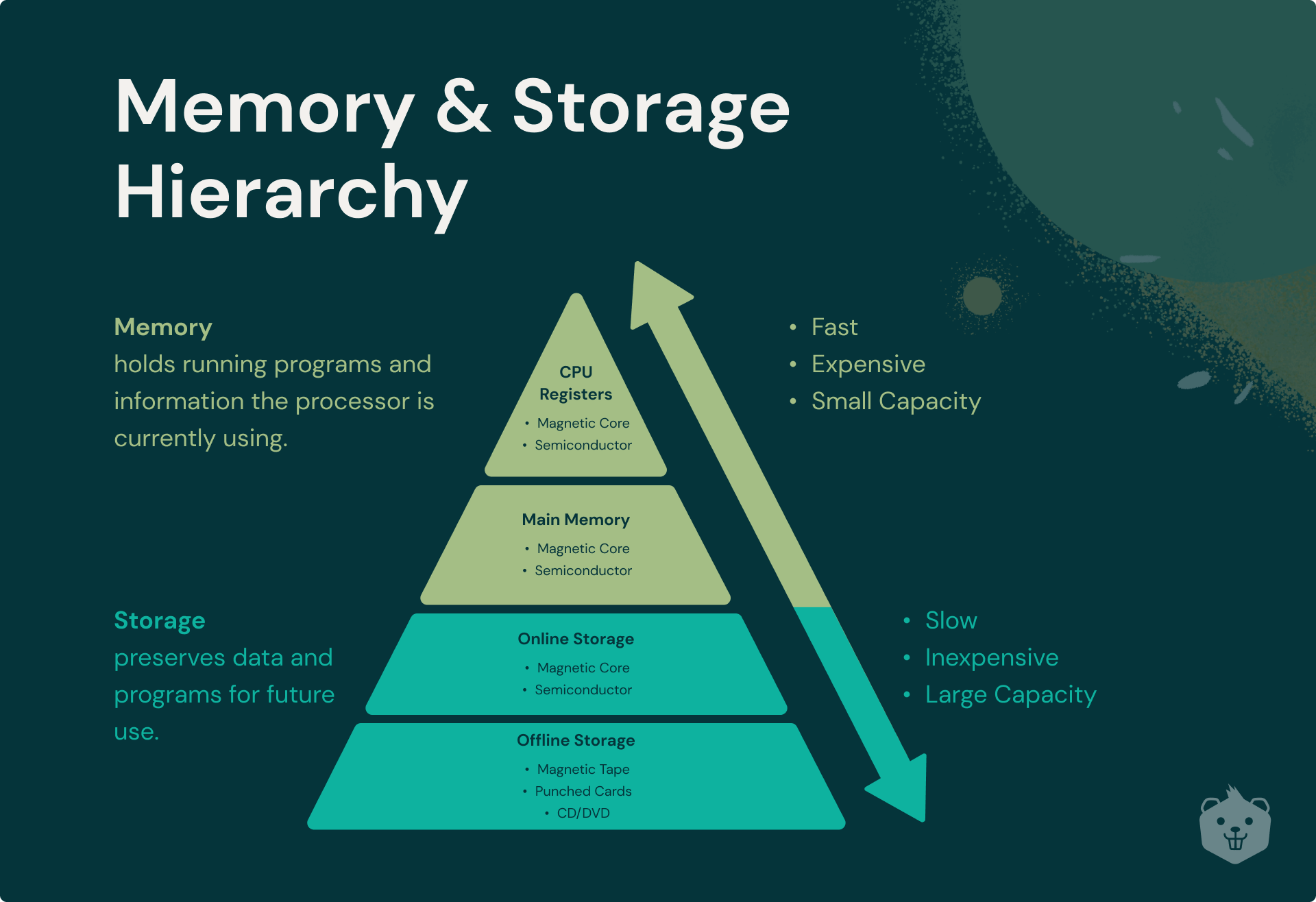
This is also why Redis is used as a cache in many applications, to provide results rapidly. But we could store our data directly on the primary memory or in the system cache, we won’t require Redis then, right?
Redis is so much more than ‘just a cache’, as you will see.
Advanced Data Structures
Redis stores its data in a key-value pair and has the ability to store the data using a variety of data structures like:
- Strings
- Lists
- Sets
- Sorted Sets
- Hashes
- Bit Arrays
- HyperLogLogs
- Streams
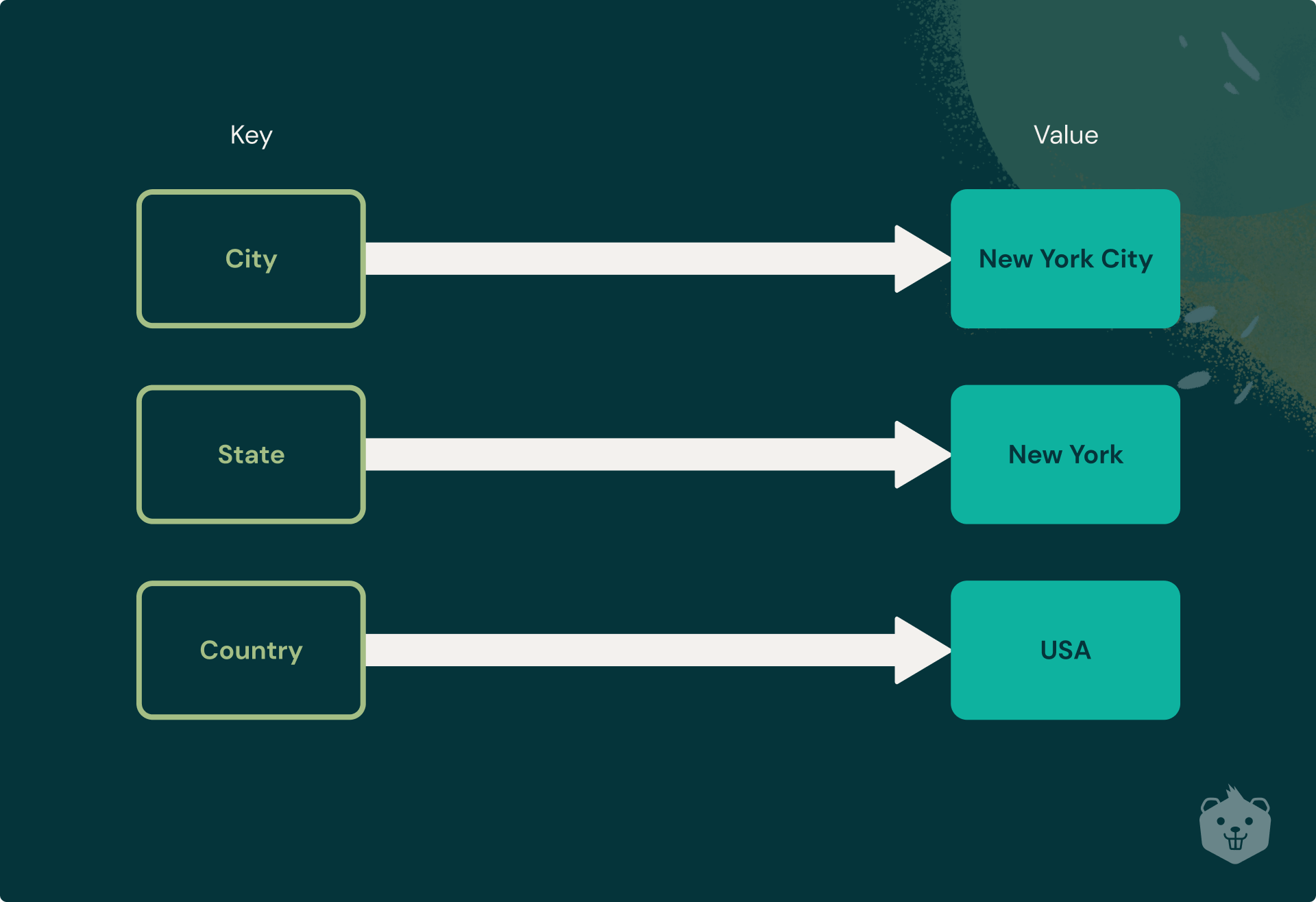
This is not possible if you would wish to store data directly in the memory, without using Redis. Even Memcached, which is another very popular in-memory key-value store used as a caching mechanism, only supports Strings but not such data structures which Redis provides.
As a developer, you must have used some of these data structures, which also makes Redis easier to use and implement.
There is no serialization required here since the data is stored directly in the form of the data structures you are coding in. Had this not been the case, you would have to convert or serialize the data into Strings before storing it into any other data store or database.
Persistence
Another disadvantage of directly using primary memory or system cache is the data being volatile. All the data on primary memory gets washed off or cleaned as soon as there is no power source or when the system is shut down.
Redis offers two mechanisms to help prevent this - Snapshots and AOFs (Append Only Files), which are basically a backup of the Redis data-store on the secondary memory, so that if there is a system failure or if there is a power outage, it can recall the current state of the database, by loading data from these backups present on the disks.
Replication
Redis uses master-slave (primary-replica) architecture, where data can be replicated to multiple replica servers. This boosts the read performance since requests can split among different servers. This also helps in faster recovery in case the master or primary server experiences an outage.
Huge Support
Being an Open Source project with a diverse community, Redis has no technology constraint, as it is based on open standards, and supports open data formats. It also supports a rich set of clients, with support in more than 40 programming languages.
Since Redis stores everything in-memory, in the form of a wide variety of data structures, and also provides persistence and the ability of replicating servers, it stands out when comparing to other databases/caches which cannot serve the same purpose as Redis.
Here is a quick comparison of Redis with other major databases and key-value stores.
Where is Redis being used?
Take a look at some prominent uses of Redis with real-world examples:
Twitter - Caching with low latency
Twitter is a social-networking site, which is much like any other social media application out there, with features like a user can create posts, like other user’s posts, comment on a post, or even follow other users. Posts in this context are tweets, but let’s keep it general.
Let’s say you’re building a social media application.
You would want to save user profiles in a cache, with information like number of posts, followers and following, so that a lot of overhead is reduced on the system, to fetch data from the database and recompute every time the user asks for it.
Similarly, when you would open the application signed in as a user, the first screen you would see is your feed or timeline, which would have posts from all the users you follow.
Now, of course, if you follow only 2-3 users, getting their posts in reverse order and then merging them is not that heavy of a computation. But if it’s a pretty big application, with millions of users, where they are following hundreds of thousands of users, this performs very poorly, as this needs to be computed for every user, every time they open the app.
This is where Redis comes into the picture and solves the problem by computing and storing all of these timelines in a cache, and serving it to the clients from there.
It’s faster, provides lower latency, and performs way better.
This is made even easier by using appropriate data structures like lists in Redis.
Twitter has its own data structures built on Redis (ziplists), to further optimize the solution.
Pinterest - Caching
Pinterest is another social media application, which uses Redis as a cache to store:
- A list of users you are following
- A list of users following you
- A list of boards you are following
- A list of users who are following your boards
- A list consisting of the boards you unfollowed after following a user
- The followers and unfollowers of each board
Similarly, Twitter and Instagram also use Redis to store their timelines, feeds and social graphs.
Dream11/My11Circle - Highly performant leaderboards with concurrent read and writes
These are the leading fantasy team gaming apps in India, with millions of users participating in contests every day. The users need to create virtual teams from real players playing on the field, from the world of cricket, football, basketball, and other sports. The users earn points according to how well their players perform in the matches.
Both of these apps make use of the sorted set data structure of Redis, to generate gaming leaderboards with millions of entries being updated in real-time.
Sorted set takes keys and keeps them in an order based on the value, so if it’s a gaming leaderboard like the ones in Dream 11, the key would be the user id and the value would be the points their team scored, the users on top having the highest points.
Since these apps are dependent on real-time events happening on the field, most users create or update their team after the playing 11 (for a cricket or football match) is announced, which is around 30 minutes prior to the start of a game.
Naturally, there is a huge load on the database to make concurrent writes and reads during this time.
Redis is highly efficient here as well, as it is an in-memory, single-threaded store, which writes data in a sequential manner. These sequential writes maintain consistency at the caching layer and have helped scale these applications.
StackOverflow - Displaying top-voted answers on top
The one site which doesn’t need any introduction to all the developers out there. For others, it’s basically a Q&A site like Quora, where technical problems are discussed.
Sorted sets are used here as well, to keep the most upvoted or liked answers on the top, to maintain good quality content.
Valorant - Load balancing across server instances
This is an FPS (First-Person-Shooter) video game, which is getting very popular and gaining a lot of traction. And with this, they have managed to create a well-scaled system.
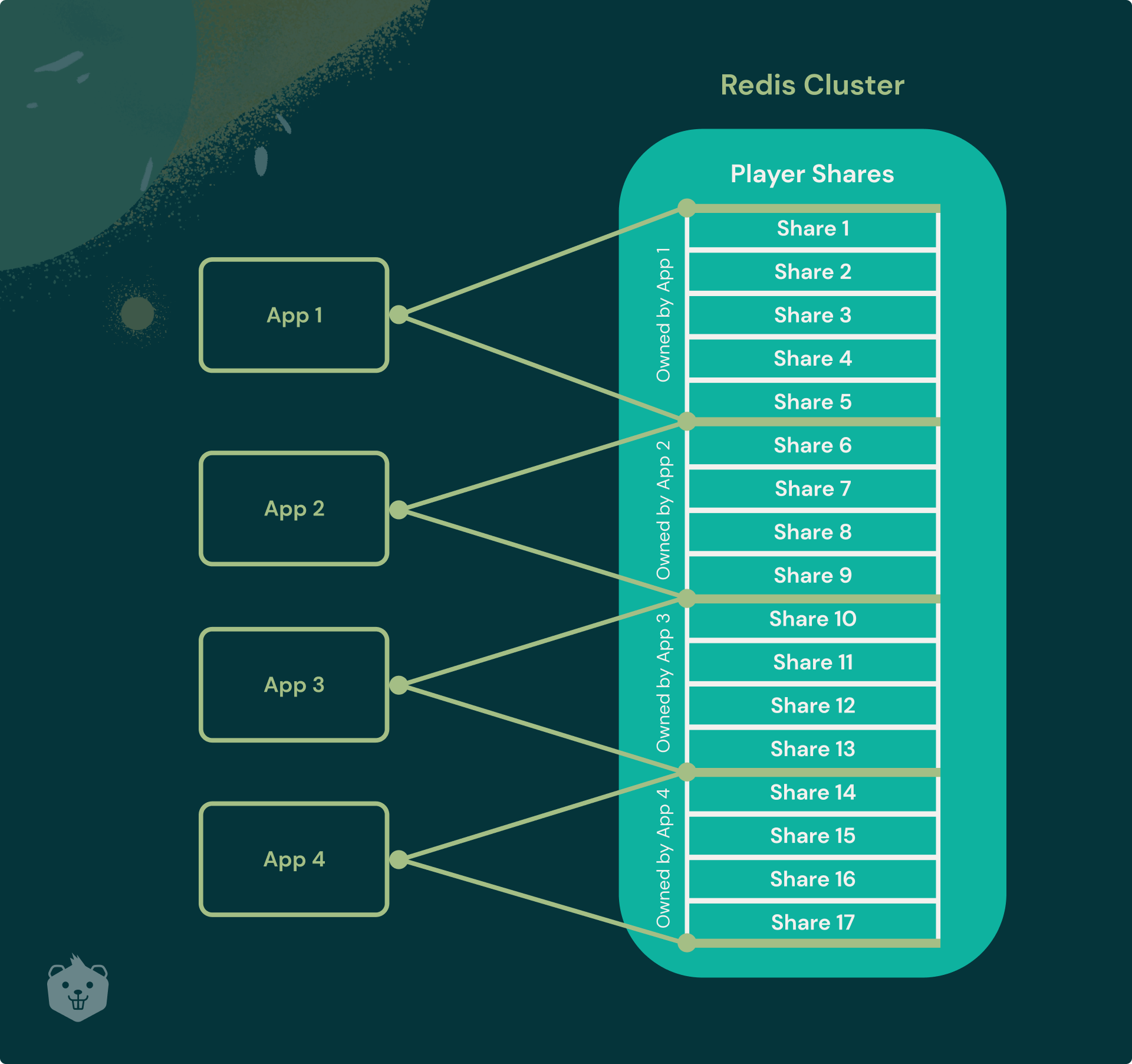
Let’s take the example of a session microservice, which checks whether a player is online or not. There are multiple instances of the application running to handle the load.
Now, if the user is disconnected or their PC crashed, which does not explicitly call or trigger the microservice, there is a question as to which session service instance should manage this, by counting whether the inactive time exceeds the threshold?
Note that this has to be done for every user at the same time.
This is being solved by using hashes, storing in a Redis cluster the user id in a list based on the modulo of their player ID hash. When the service starts, each app instance checks the list and takes up a share of users by registering their own instance ID. When there are additional instances started to handle the load, the shares get distributed evenly amongst the instances.
Dream11 also uses Redis for a similar use case of task distribution.
Doordash - Machine Learning inference with low latency
Doordash is an online food delivery company, which is the largest food delivery company in the United States. Being such a large company, with millions of users, and since they also build Machine Learning (ML) models, they have feature data that can grow to billions of records with millions of records being used for inference in real-time.
Machine Learning inference is the process of running live data points into an ML model to calculate the score, and feature data is basically the input given to an ML model during inference.
To match the low latency constraints while processing such a large dataset in real-time, Redis hashes are being used, which when benchmarked with other competitor software, performs the best.
Home Depot - Real-time data analytics
Home Depot is the largest home improvement retailer in the United States, providing tools and construction products.
Redis powers their order management system which is designed to process 30k transactions per second.
Sorted sets and Geodata structures are used for inventory forecasting and calculation in real-time, while hyperloglogs are used to count the number of unique customers, sales per item and sales per category.
Similarly, many other applications use Redis for Real-time analytics, like fraud or spam detection systems, because Redis is capable of reading and writing large amounts of data with low latencies.
As a message broker
This is when there is a channel or a group of users, where they can push or view messages, like a Whatsapp group or a Telegram Channel. This is a Pub/Sub model, where there are publishers and subscribers. Every time a new message is created or published, all the subscribers or listeners receive the message.
Redis supports this feature and is blazingly fast.
As a session store
Redis is also used to maintain and store the session of a user in an application.
Like in an e-commerce application, you would want the items in your cart to persist even when you close the site. It is also very common to store user metadata, like profiles and credentials, and Redis is the most popular choice in these scenarios.
When to avoid using Redis
Using Redis as the sole database
Since Redis is an in-memory key-value store, all the data must fit in the memory. It’s storage size is dependent on how much RAM or primary memory is present in the system, which is much less in size and more costly when compared to hard disks.
So, it should not be used as the only database for very large applications.
Redis is used mainly with other RDBMS to supplement them by providing a caching mechanism.
Using Redis as a transactional server
Another pitfall of having storage in memory is security. Although Redis provides solutions for persistence, it is still not as secure as a real transactional server, which provides redo/undo logging, block checksumming, point-in-time recovery, flashback capabilities, etc.
Using Redis as a Relational Database
Redis is a data structure server, which unlike any RDBMS, does not provide a query language and there is no support for any relational algebra. So, the developer has to anticipate all the data accesses and needs to define proper data access paths, which means a lot of flexibility is lost.
Redis is more complex to scale
Since Redis is synchronous and single-threaded, it does not fully utilize all the cores of a processor. This makes scaling more difficult or complicated to implement as several Redis instances must be deployed and started (forming clusters).
Alternatives to Redis
A major competitor of Redis in caching is Memcached, which provides multithreading.
MongoDB is another choice of NoSQL database, as it provides document-oriented storage with its own query language.
RabbitMQ is one of the most used message brokers, and is more durable and preferred over Redis, even though it’s more complicated.
Cassandra is a partitioned row store, in which rows are organized into tables with a required primary key. This is highly used for its easy-to-scale capabilities, and for being more fault-tolerant.
Final thoughts
As you can see, Redis is basically a swiss army knife and has multiple use cases in the real world. I hope that now you have a better knowledge of how these real-world applications use Redis, and what causes your feeds and gaming leaderboards to update in real-time.






