Learn about HTTP protocol and how it’s used
Objective
Background
HTTP is the most popular application protocol on the internet, which makes actions like internet browsing happen. It starts with a client machine sending requests in the HTTP format. The server machine receives the request, understands it and takes appropriate action. The response again has to be formatted in a specific manner adhering to the HTTP protocol for the client to make sense of it.
Primary goals
-
Get a clear understanding of how HTTP works.
-
Use tools like cURL & Postman to perform HTTP requests and analyse responses
Objective
Learn about HTTP protocol and how it’s used
Background
HTTP is the most popular application protocol on the internet, which makes actions like internet browsing happen. It starts with a client machine sending requests in the HTTP format. The server machine receives the request, understands it and takes appropriate action. The response again has to be formatted in a specific manner adhering to the HTTP protocol for the client to make sense of it.
Primary goals
-
Get a clear understanding of how HTTP works.
-
Use tools like cURL & Postman to perform HTTP requests and analyse responses
Understanding HTTP using Browsers
HTTP stands for HyperText Transfer Protocol. It is, like the name suggests, a set of rules for querying the web. It works on a client-server model, where the client, in most cases, the browser, makes a request, and waits for the server to respond.
Browsers use HTTP Requests to fetch us web pages. When we enter a website URL, the browser creates a HTTP Request on our behalf and sends it to the server on which the website is hosted. The HTTP Response from the server is read by the browser and rendered for us beautifully as web pages instead of the raw HTML returned. Let’s look into what constitutes a HTTP request & response
TODO -
-
Open a new window on Google Chrome and navigate to https://www.flipkart.com/ in Incognito (To avoid inconsistencies due to caching).
-
Open Chrome Developer Tools
Ctrl + Shift + i/Cmd + Shift + iin the browser window and select theNetworktab. -
Refresh the page to start recording network activity from Chrome and observe the HTTP requests made to load the website.
-
How many HTTP requests were made?
-
How much data was transferred over the network?
-
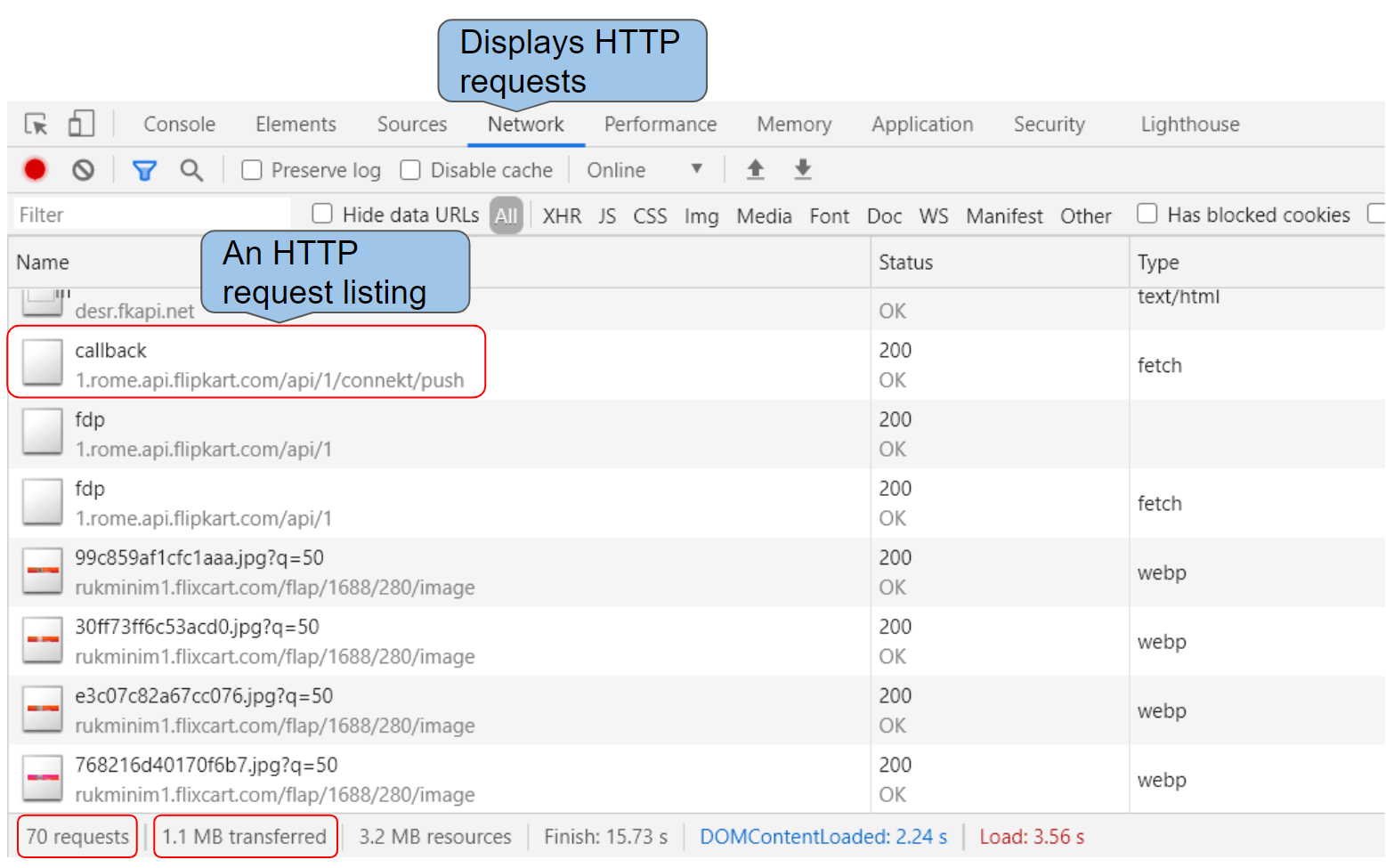
HTTP Requests listed in the Network tab
Each of the images, CSS file, JavaScript file or any other resource the website uses requires an HTTP request each.
TODO -
- Scroll to the top of the network activity and click on the first request made to open up its details. (Find the entry In the
Nametab, you should seewww.flipkart.comwithTypeas document).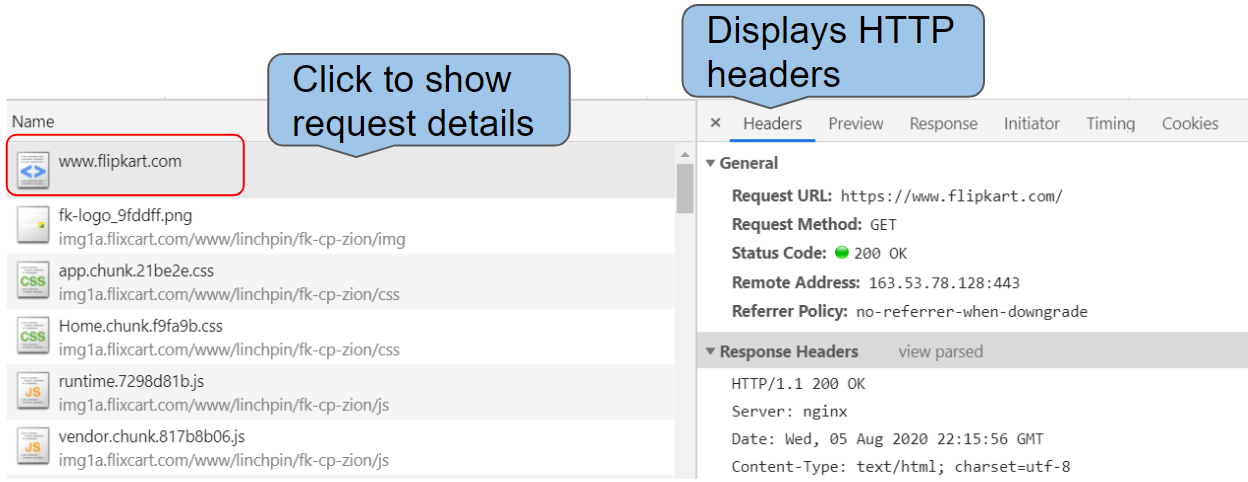
Details of an HTTP Request
-
Observe the following details for this HTTP request in the "General" section
-
Request URL - URL of the resource fetched
-
Request Method - denotes the action to be done. "GET" is for fetching some resource
-
Status Code - denotes how the server responded to the request. "200 OK" means a successful request and as this is a “GET” request, server will have sent some data back i.e, website’s HTML content
-

-
Check the "Remote Address" value in the “General” section - The port number used is 443. Is this a special port number? Is there any relationship between the port number used and the Request URL? Why is there a lock icon in the address bar of your browser?

-
Check out some of the Response Headers and see if you can find out what they mean. eg: Content-Type, Server
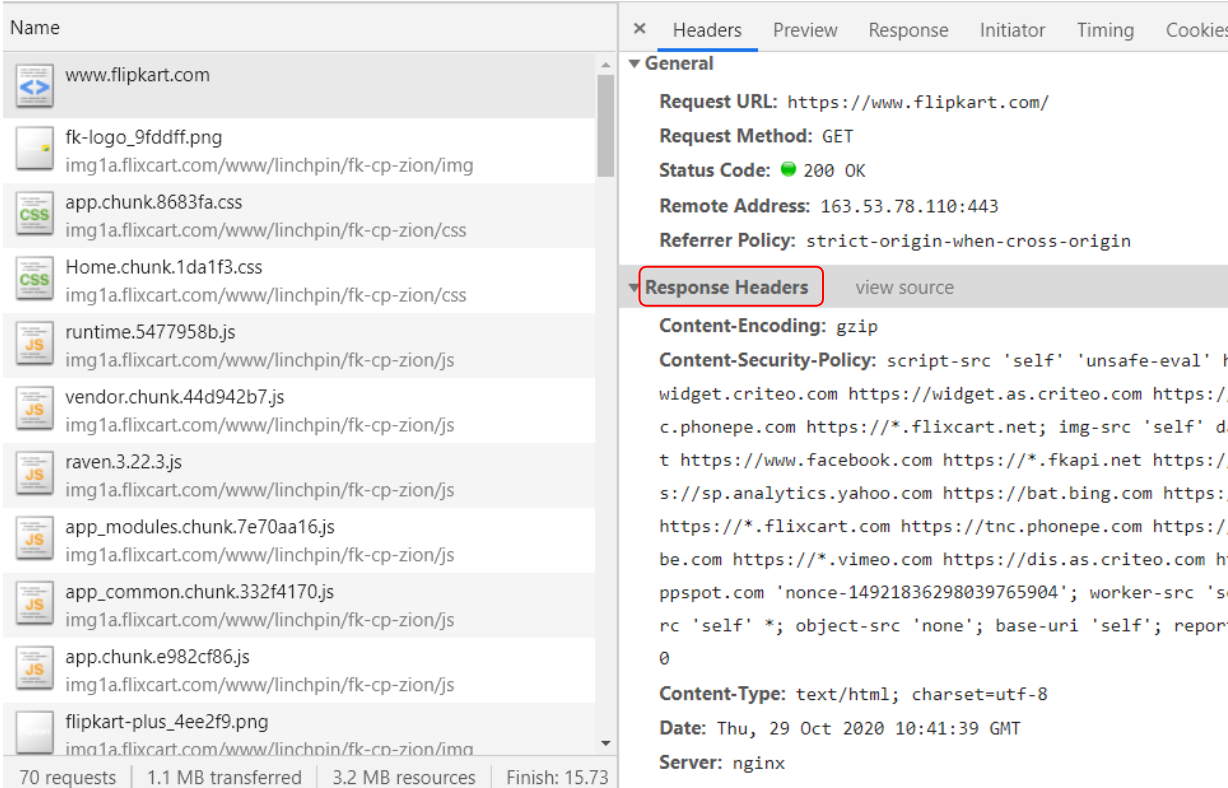
- The HTTP request-line contains the HTTP method used, path of the resource fetched and the HTTP version client is using. Find out the HTTP request-line sent by your browser to the Flipkart server (Hint: Click on view source next to Request Headers)
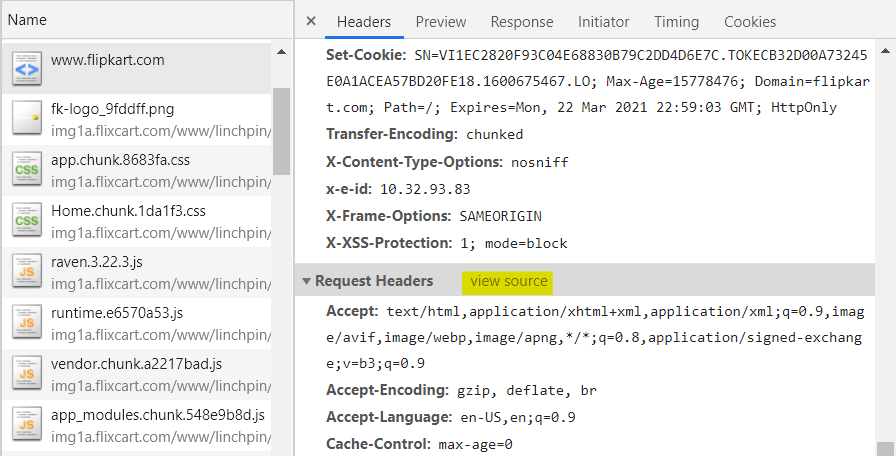
- Goto https://www.flipkart.com/television-store in a new tab. What do you think would be the changes in the HTTP request-line? Verify by checking the request-line sent for retrieving the new HTML page like you did in the previous step. (Filter for
Docto easily find requests for HTML files)

You’ll have found that the request line will now be asking for the resource at /television-store instead of the resource at root (/) when you visited https://www.flipkart.com/. The Host request header tells where to fetch this resource from.
GET /television-store HTTP/1.1
Host: www.flipkart.com
Curious Cats
-
Suppose Chrome versions below 80.0 don't support GIF images. We need our server to return a corresponding PNG image if any unsupported browser asks for the GIF image. How would the server know the Chrome version from which the request was made? (Hint: See Request Headers)
-
Open a browser tab in Incognito. Visit https://crio.do/ after opening the Networks tab in DevTools. Observe the size of data transferred. Open a new tab and do the same. Is there a difference in the size of data transferred now? Inspect the request & response headers in both situations to find out what’s happening.
-
We looked at how requesting for a HTML file inturn creates a new HTTP request to fetch resources like scripts & images within it. Visit a couple of websites & inspect the resources loaded. Is there any order in which the resources are loaded? Does HTTP mandate this?
-
HTTP is a ‘stateless protocol’, meaning two corresponding requests do not share data - your prior request is not ‘remembered’ in any way by the following one - this obviously has some flip sides - you might need to keep resending data that you want to persist through requests - why is it still designed this way?
Answers to these Curious Cats questions will be available in the Takeaways milestone at the end.
Understanding HTTP using Browsers
HTTP stands for HyperText Transfer Protocol. It is, like the name suggests, a set of rules for querying the web. It works on a client-server model, where the client, in most cases, the browser, makes a request, and waits for the server to respond.
Browsers use HTTP Requests to fetch us web pages. When we enter a website URL, the browser creates a HTTP Request on our behalf and sends it to the server on which the website is hosted. The HTTP Response from the server is read by the browser and rendered for us beautifully as web pages instead of the raw HTML returned. Let’s look into what constitutes a HTTP request & response
TODO -
-
Open a new window on Google Chrome and navigate to https://www.flipkart.com/ in Incognito (To avoid inconsistencies due to caching).
-
Open Chrome Developer Tools
Ctrl + Shift + i/Cmd + Shift + iin the browser window and select theNetworktab. -
Refresh the page to start recording network activity from Chrome and observe the HTTP requests made to load the website.
-
How many HTTP requests were made?
-
How much data was transferred over the network?
-
HTTP Requests listed in the Network tab
Each of the images, CSS file, JavaScript file or any other resource the website uses requires an HTTP request each.
TODO -
- Scroll to the top of the network activity and click on the first request made to open up its details. (Find the entry In the
Nametab, you should seewww.flipkart.comwithTypeas document).
Details of an HTTP Request
-
Observe the following details for this HTTP request in the "General" section
-
Request URL - URL of the resource fetched
-
Request Method - denotes the action to be done. "GET" is for fetching some resource
-
Status Code - denotes how the server responded to the request. "200 OK" means a successful request and as this is a “GET” request, server will have sent some data back i.e, website’s HTML content
-
-
Check the "Remote Address" value in the “General” section - The port number used is 443. Is this a special port number? Is there any relationship between the port number used and the Request URL? Why is there a lock icon in the address bar of your browser?
-
Check out some of the Response Headers and see if you can find out what they mean. eg: Content-Type, Server
- The HTTP request-line contains the HTTP method used, path of the resource fetched and the HTTP version client is using. Find out the HTTP request-line sent by your browser to the Flipkart server (Hint: Click on view source next to Request Headers)
- Goto https://www.flipkart.com/television-store in a new tab. What do you think would be the changes in the HTTP request-line? Verify by checking the request-line sent for retrieving the new HTML page like you did in the previous step. (Filter for
Docto easily find requests for HTML files)
You’ll have found that the request line will now be asking for the resource at /television-store instead of the resource at root (/) when you visited https://www.flipkart.com/. The Host request header tells where to fetch this resource from.
GET /television-store HTTP/1.1
Host: www.flipkart.com
Curious Cats
-
Suppose Chrome versions below 80.0 don't support GIF images. We need our server to return a corresponding PNG image if any unsupported browser asks for the GIF image. How would the server know the Chrome version from which the request was made? (Hint: See Request Headers)
-
Open a browser tab in Incognito. Visit https://crio.do/ after opening the Networks tab in DevTools. Observe the size of data transferred. Open a new tab and do the same. Is there a difference in the size of data transferred now? Inspect the request & response headers in both situations to find out what’s happening.
-
We looked at how requesting for a HTML file inturn creates a new HTTP request to fetch resources like scripts & images within it. Visit a couple of websites & inspect the resources loaded. Is there any order in which the resources are loaded? Does HTTP mandate this?
-
HTTP is a ‘stateless protocol’, meaning two corresponding requests do not share data - your prior request is not ‘remembered’ in any way by the following one - this obviously has some flip sides - you might need to keep resending data that you want to persist through requests - why is it still designed this way?
Answers to these Curious Cats questions will be available in the Takeaways milestone at the end.
What are HTTP Request Methods?
We saw how HTTP can be used to fetch data in Milestone 1. How would we use HTTP to
-
Upload data to the server eg: Add profile picture to facebook
-
Update some data present in the server eg: Change your facebook display name
-
Delete some data present in the server eg: Remove contact information from facebook
As listed above there are a variety of use cases and HTTP provides different request methods for each. Let’s look at the most frequently used methods.
GET
GET requests are used to "get" resources from a server. By definition, GET requests **should **only fetch data from the server and shouldn’t change the data stored on the server.
Check the requests made when you visit https://gitlab.crio.do/users/sign_in in Incognito. If we check the first request made, it’s for a resource of type document which is the HTML file. Use the Preview tab to see the HTML rendered. Is it missing something?
Goto the Response tab & you’ll be able to see the raw HTML data. You’ll be able to see <img> tags. Why aren't the images showing up in the Preview tab then?
As we saw earlier, we can only specify a single resource in the HTTP request-line at a time meaning that we need a separate HTTP request for fetching any related files (image, css, javascript) the HTML needs.
Find out an image included in the HTML (look for <img> tags). Can you see a HTTP request for that resource?

POST
POST requests are used to send some data to the server. Some use cases are to submit data from a web form or to upload a file to the server.
Assuming you’re still at https://gitlab.crio.do/users/sign_in, try to Sign in using some invalid credentials. Inspect the request sent now. How does it differ from what we had when we visited the web page?
Scroll down in the Headers tab to find the form data you filled which was sent along with the HTTP request.

PUT
PUT requests are used to update data on the server side. This could be for actions like changing your Facebook relationship status, updating a student’s marks on the college server after improvement exams etc.
Visit https://gitlab.crio.do/ and login using Google sign-in if you haven’t already. Open the DevTools Networks tab and ensure you’ve the Preserve log option checked.
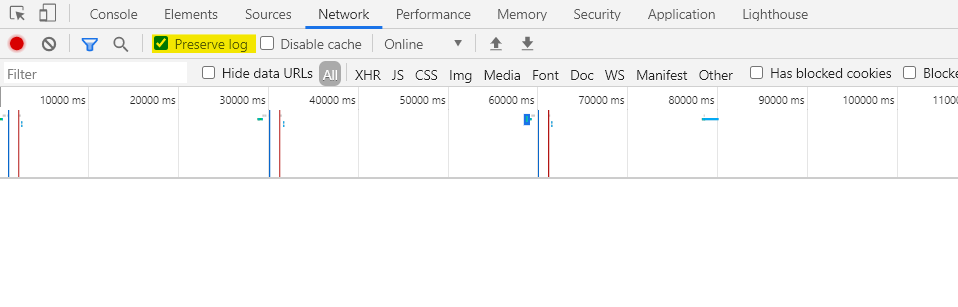
Try updating your account status (Yep, even Gitlab allows you to set status :)) and monitor the network requests. Are there any PUT requests made?
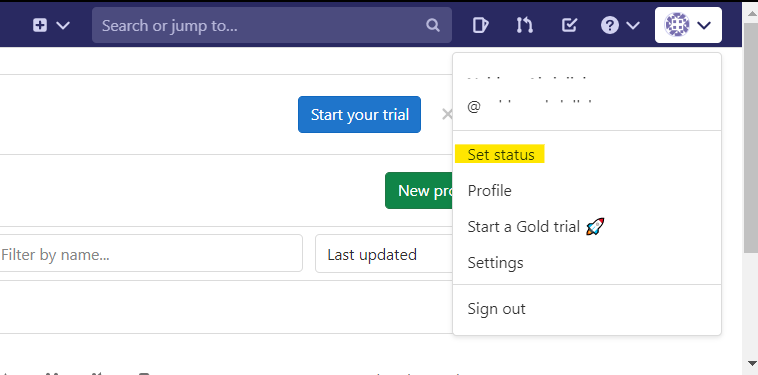
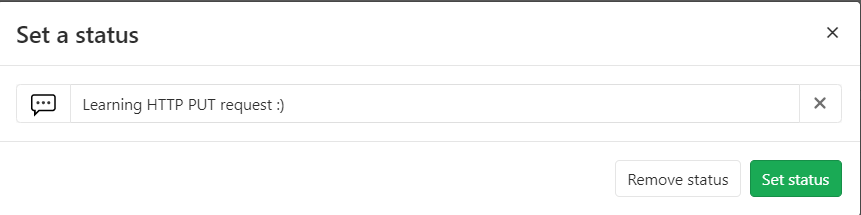
Try the same process again with the Preserve log option unchecked. Are there any differences? Why so?
We looked at some of the commonly used HTTP request methods. There are a few more that we can use to perform tasks like deleting data, finding the request methods supported for a particular endpoint etc.
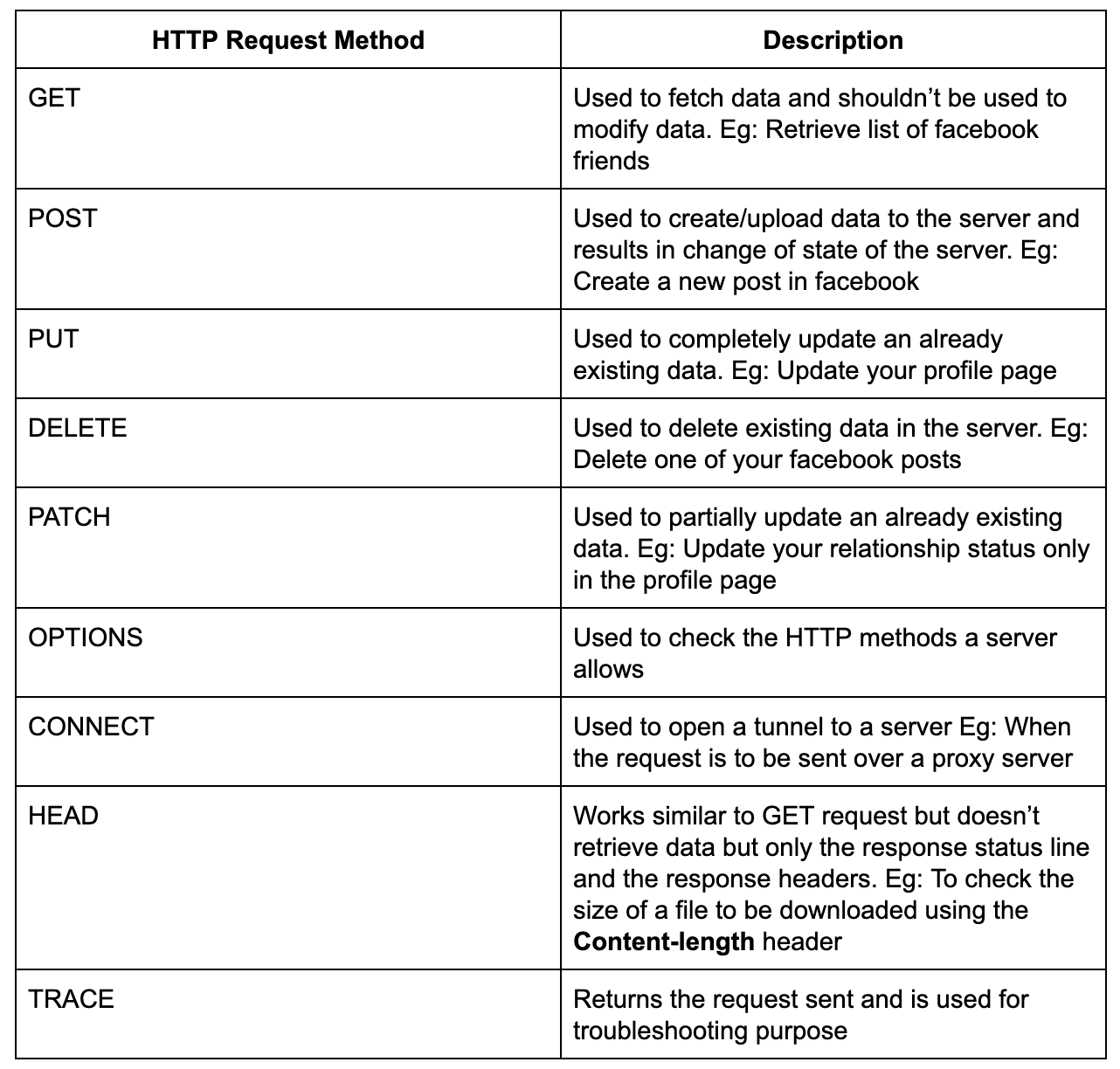
Curious Cats
-
Is it possible to send form data using a GET request? Why or why not?
-
Are there any limitations in using a GET request to send data to the server?
Answers to these Curious Cats questions will be available in the Takeaways milestone at the end.
What are HTTP Status Codes?
HTTP Status codes are part of the HTTP Response. It helps the client understand what happened to the request. Status codes are 3 digit numbers (201, 304 etc) and are categorised to 5 different families based on their starting digit. Along with the status code, a Reason-Phrase is also present (OK, Moved Permanently etc) which gives a short description of the status code. The Status Code is intended for machines whereas Reason-Phrase is for humans.

Status codes - 2xx
The 2xx family of status codes or status codes 200-299 signifies the HTTP request was successfully received & understood by the server. We’ve been seeing the 200 status codes all the way until now. That’s what we get when the server returns some resource for our request.
Status codes - 3xx
3xx family of status codes denotes that further action must be taken to complete the HTTP request made.
-
Try navigating to http://www.flipkart.com instead of https://www.flipkart.com (
httpinstead ofhttps). -
Observe the headers of the first HTTP request again this time.
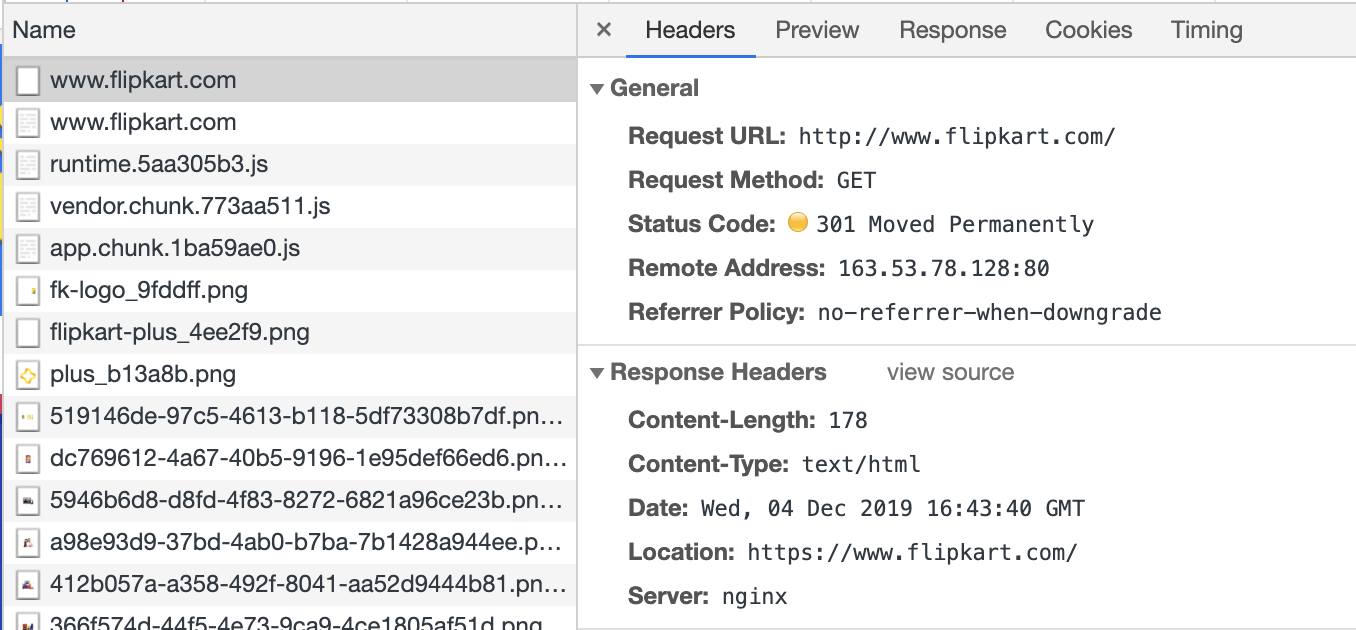
-
Note the response status code:
301 Moved Permanently. This is Flipkart asking the browser to redirect the request from the unsecure URL (http://) to the secure URL (https://) instead. The browser will oblige and send the request accordingly. -
Inspect the Remote Address again. Is the IP address the same as before? What about the port number?
-
What is the difference between port
80and port443? -
How does the browser know to redirect to https://www.flipkart.com? (Hint: Response Headers)
-
In summary, requests to http://www.flipkart.com get redirected to https://www.flipkart.com.
Status codes - 4xx
Getting a 4xx status code tells us that there was an error in the HTTP request sent by the client - that would be the browser if we are visiting web pages.
Check the status code on trying to fetch some random resource from a website eg: https://www.flipkart.com/crio-do
There are a couple more HTTP status code families - 1xx & 5xx. 1xx is for information purposes while 5xx signifies there was a server error.
Here’s a fun illustration for you to remember the status codes easily. If some of them don’t make sense, check out this reference(https://developer.mozilla.org/en-US/docs/Web/HTTP/Status) to find out what they mean.
Curious Cats
-
When you try to access a resource that requires logging in, like LinkedIn feed, https://www.linkedin.com/feed, you get redirected to the login screen. That should be a 301, right? Can you verify.
-
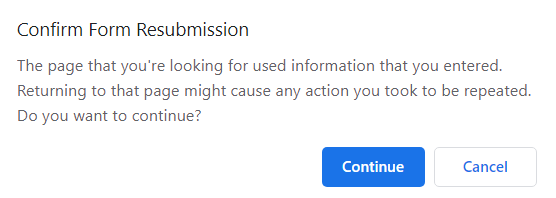
One day or another, you’d have come across the below pop-up when trying to reload a web page containing a form. Why does this happen? Is there any way to avoid this happening?
-
Find out example situations that result in a 4xx or 5xx response code.
Answers to these Curious Cats questions will be available in the Takeaways milestone at the end.
Open a Linux terminal
Note
If you are taking this Byte on your personal Linux machine or on Gitpod(https://gitpod.io/#https://gitlab.com/crio-bytes/me_http), open a new terminal and skip to the Setup Dependencies section below.
Instructions for the Crio Workspace
To open a terminal in the Crio Workspace, follow the steps below:
-
Click on the workspace icon on the left sidebar and click on the
Startbutton to create your workspace. -
Once your workspace is ready, click on
Launch online IDE. -
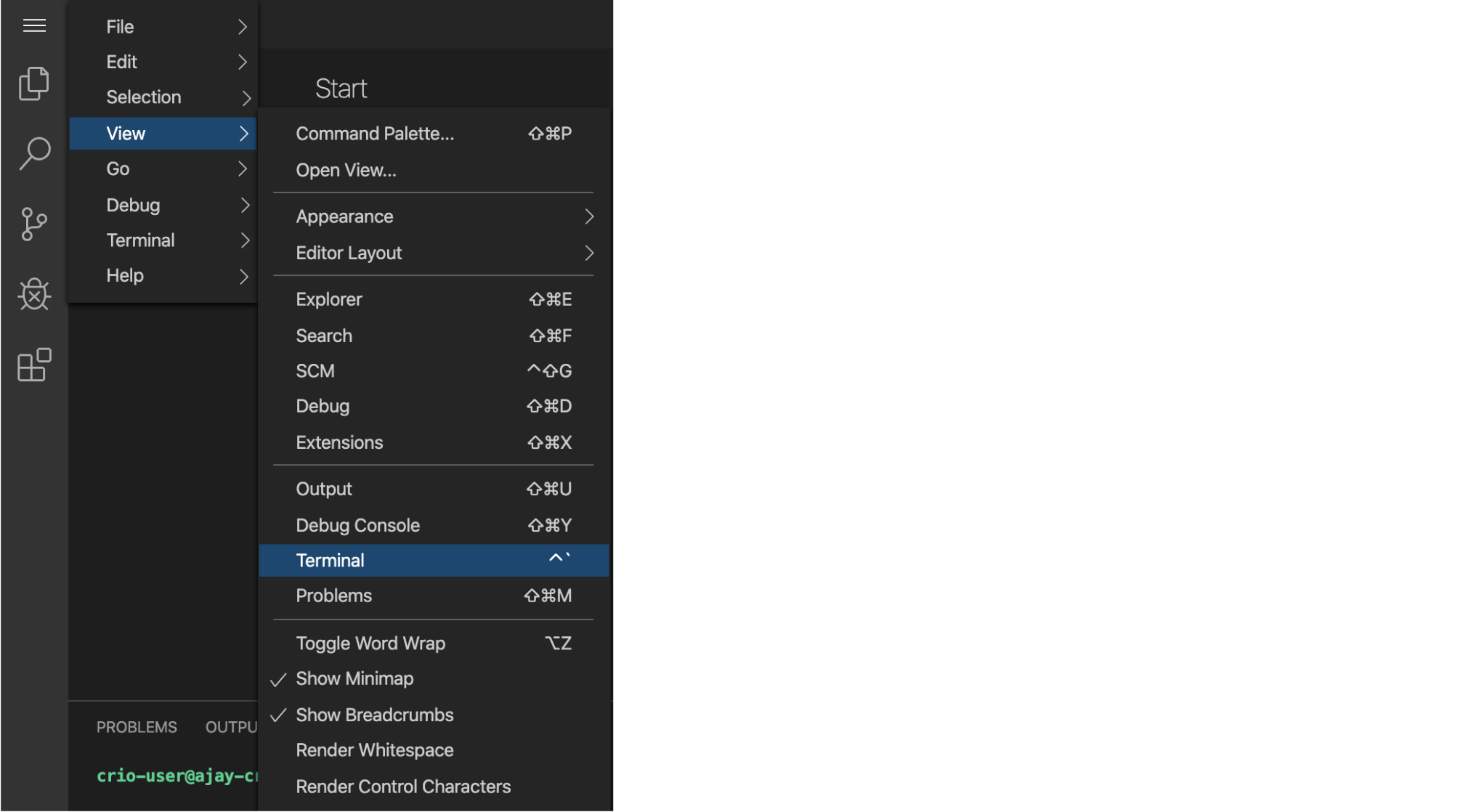
Click on
View > Open in New Taboption (see image below).
- Open a new terminal, click on the
Menu > View > Terminal. (Note: The menu button is on the top-left (three horizontal bars).
The cURL utility
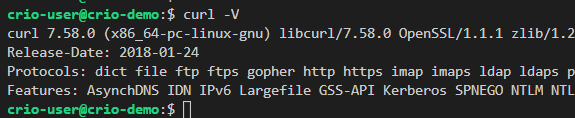
cURL is like a web-browser, but for the command line.You can make HTTP requests using cURL just like in a web-browser. The Response can be seen on the command line or redirected to a file.
Open a new terminal window and enter the following commands. Take your time and observe the output of each step closely.
-
Type the following
curlcommand:curl -X GET https://www.flipkart.com -o ~/flipkart.htmlThe output of the curl command goes to a file called flipkart.html. You can typemore ~/flipkart.htmlorcat ~/flipkart.htmlto see the contents of flipkart.html file. -
In the above
curlrequest,-Xallows you to specify the HTTP method to be used. -
You don’t have to use the
-X GETswitch => it is the default behaviour. Try the following command:curl https://www.flipkart.com -
curlcan give you the same details that you were looking at, in the Chrome Developer Tools.
Try the below exercises and inspect the content of the flipkart.html file
-
curl -X GET http://www.flipkart.com -o flipkart.htmlYou should see the301 Moved Permanentlyreponse; just like in Chrome Developer Tools -
We can also print the HTTP Response Headers using this:
curl -i -X GET http://www.flipkart.com -o flipkart.htmlNow, you should see the full Response Headers as well. -
If you also want the full details, try the following command:
curl -v -X GET http://www.flipkart.com -o flipkart.htmlA verbose log is printed. You can get the IP Address and the port number from the console output this time. -
You can also instruct
curlto follow the Redirect uRL automatically using the-Lswitchcurl -v -L -X GET http://www.flipkart.com -o flipkart.html # still using http and not https
Can you find out other capabilities of cURL?
Postman (Optional)
Postman is a powerful GUI based application that lets us make HTTP requests easily. To start with, create a new Request in Postman.
You’ll be able to see this view
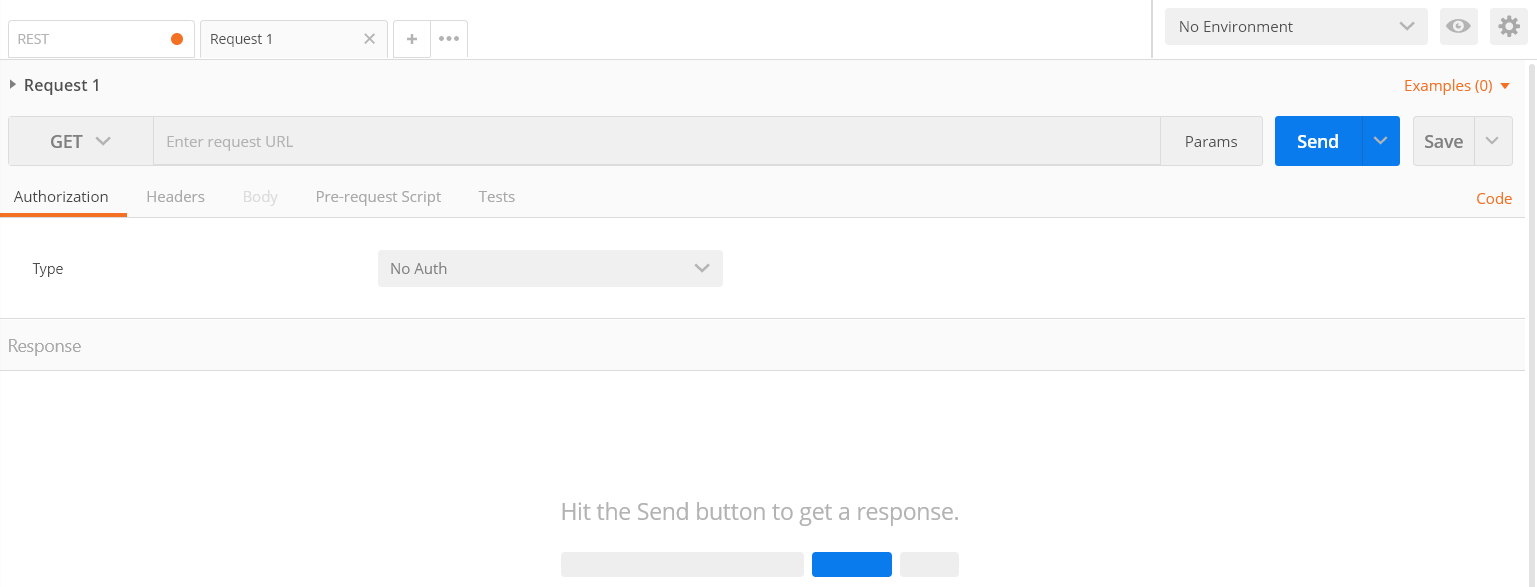
Using Postman to perform GET requests is straightforward. Just add the request URL and hit Send.Try performing a GET request for https://www.flipkart.com.

The returned data is shown in the Body tab and the response headers in the Headers tab. Check the headers out.
Curious Cats
- Postman has a cool feature presenting us with commands to perform requests using cURL, Java, Python & multiple other languages. Find out how to do that.
Answers to these Curious Cats questions will be available in the Takeaways milestone at the end.