Learn abstraction by applying it in a practical scenario.
Objective
Background
Abstraction is the concept of exposing only the required information to users and hiding the rest. A class would only expose some of its methods and hide the data fields and other methods. For the exposed methods, the users only need to worry about the method name, the input parameters that need to be passed and the output format to expect. The external users/objects need not worry about the complexity within these methods.
Abstraction is a natural extension of encapsulation.
This is very useful in large projects which have many different kinds of objects interacting with each other. It keeps the complexity manageable. Each class is free to make changes under the hood without impacting other classes as long as the exposed interface doesn't change.
An abstract class or interface is a good way to implement Abstraction. The methods and their signature (inputs and outputs) are made public by the abstract class or interface and multiple other classes can implement these methods. That way, we can switch between the implementing classes without much impact to external entities that use these methods.
In this Byte, we’ll experience where Abstraction is useful and how it contributes to better software design.
Primary goals
-
Learn where Abstraction can be used
-
Understand why it is needed and to how to apply it
Objective
Learn abstraction by applying it in a practical scenario.
Background
Abstraction is the concept of exposing only the required information to users and hiding the rest. A class would only expose some of its methods and hide the data fields and other methods. For the exposed methods, the users only need to worry about the method name, the input parameters that need to be passed and the output format to expect. The external users/objects need not worry about the complexity within these methods.
Abstraction is a natural extension of encapsulation.
This is very useful in large projects which have many different kinds of objects interacting with each other. It keeps the complexity manageable. Each class is free to make changes under the hood without impacting other classes as long as the exposed interface doesn't change.
An abstract class or interface is a good way to implement Abstraction. The methods and their signature (inputs and outputs) are made public by the abstract class or interface and multiple other classes can implement these methods. That way, we can switch between the implementing classes without much impact to external entities that use these methods.
In this Byte, we’ll experience where Abstraction is useful and how it contributes to better software design.
Primary goals
-
Learn where Abstraction can be used
-
Understand why it is needed and to how to apply it
Getting Started
You can download the source code from gitlab by executing one of the following commands:
git clone https://gitlab.crio.do/crio_bytes/me_abstraction.git
git clone git@gitlab.crio.do:crio_bytes/me_abstraction.git
If you don’t have Git already installed. Use this as a reference to help yourselves do that.
Execute this command in terminal to download the dependencies
pip3 install -r requirements.txt
Verify by running the oop_way/main.py file
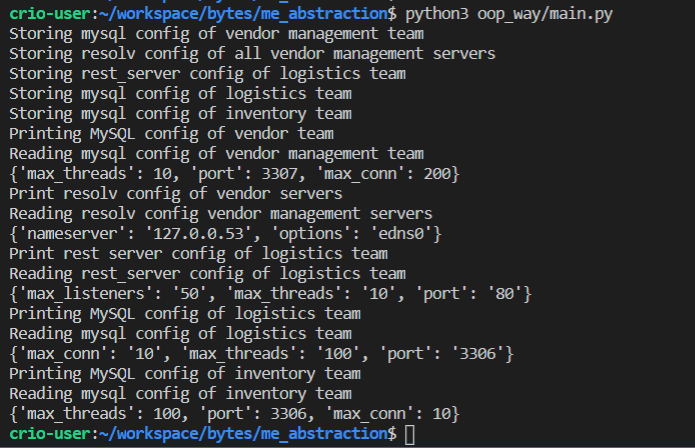
Current design to read and write configuration data
A well known online shopping site like Flipkart or Amazon has many products (or micro-services) that work behind the scenes. Some of these are user session management, inventory management, logistics, vendor management, search etc. These come together to take orders, orchestrate and finally deliver the order to the customer.
Developers of each of these products maintain many configuration parameters like shopping_cart_timeout_value, default_payment_mode, etc. at product level.
When these products come up, or after they are up, they will read configuration parameters and use that to tune the way they function. Configuration files provide a quick way to store configuration data.
Since we have multiple product teams, we have built a common Config Manager that all the products can leverage to read or update their configuration parameters.
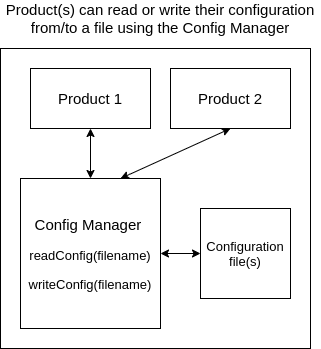
The Config Manager currently supports configuration in the form of a JSON file. Each product has its own file(s) to store configuration. The Config Manager reads configuration of a product from its JSON configuration file and provides this information to the product. It also writes back to the file when the product wants to make configuration changes/updates.
Sample JSON file
{
"max_threads": 100,
"port": 3306,
"max_conn": 10
}
Code Structure
Fetch the code from this git repo as specified in the Setup & Getting Started task if you haven’t already.
Let’s look at how our current implementation is laid out & what the different project files are. We have version 1 inside the base_code/ directory. Files we have are:
-
config/config_manager.py - has utility methods for reading & writing data to the config file in JSON format. Multiple teams will use the methods offered by this Config Manager.
-
inventory_hardware.py - contains methods required to read/write configuration related to the MySQL database of the inventory team, to JSON files.
-
logistics_hardware.py - contains methods required to read/write configuration related to the MySQL database & REST server used by the logistics team, to JSON files.
-
vendor_hardware.py - contains methods required to read/write configuration related to the MySQL database & resolv configuration for DNS resolver of the vendor management team, to JSON files.
-
main.py - calls the respective methods of products to demonstrate the writing and reading of their configuration files.
-
config_files/ - this directory will be the location where all the configuration files are stored. It is not initially present and will be created and populated with files when you execute main.py.
Let’s go a bit more in depth to understand what’s happening.
config/config_manager.py contains ConfigManager class which implements two methods read_config() & write_config() for interacting with the config files. The files will be stored inside the base_code/config_files directory. Currently, we’re going with the JSON format to store our configurations as it is pretty common & easy to deal with.
class ConfigManager:
CONFIG_FOLDER = 'base_code/config_files/'
@staticmethod
def read_config(filename):
with open(ConfigManager.CONFIG_FOLDER + filename) as inputfile:
try:
config_data = json.load(inputfile)
return config_data
except:
print('Seems the file is empty. Not a problem')
@staticmethod
def write_config(filename, config_data):
with open(ConfigManager.CONFIG_FOLDER + filename, 'w') as outfile:
json.dump(config_data, outfile)
outfile.write('\n')
We have many product teams that have to deal with multiple types of configuration. All of them have similar implementations that utilize the ConfigManager class methods, for reading/storing specific configuration from/to disk as JSON. For example, the Inventory team’s config handler is inventory_hardware.py
from config.config_manager import ConfigManager
def store_mysql_config(mysql_config):
print('Storing mysql config of inventory team')
ConfigManager.write_config('inventory_mysql_config.json', mysql_config)
def read_mysql_config():
print('Reading mysql config of inventory team')
mysql_config = ConfigManager.read_config('inventory_mysql_config.json')
return mysql_config
If we see, the store_mysql_config() method stores the MySQL configuration in a file named inventory_mysql_config.json. Can you quickly check the methods that the Logistics & the Vendor Management teams have?
To demonstrate our implementation, we’ll use the main.py file. It calls the methods used by all our teams. In the real product, the same methods may be invoked from a different place. Let’s see how the inventory team’s configurations are called using the methods in inventory_hardware.py
import inventory_hardware
if __name__== "__main__":
inventory_mysql_config = {}
inventory_mysql_config['max_threads'] = 100
inventory_mysql_config['port'] = 3306
inventory_mysql_config['max_conn'] = 10
inventory_hardware.store_mysql_config(inventory_mysql_config)
As you can see, the configurations are first added by use of a dictionary object and then passed to the store_mysql_config() method we saw earlier to work its magic!
The main.py file has code to interact with other methods as well. Try running the file using the below command in the terminal, you can see the base_code/config_files created & the configuration files of all of our teams populated inside it.
python3 base_code/main.py
Support for XML configuration file
Some teams want to move towards XML file based configuration instead of JSON, since XML supports a good set of tools to build, encode, validate and build schemas.
Sample XML file
<?xml version="1.0" encoding="UTF-8"?>
<configuration version="1.0" xmlns:xsi="[http://www.w3.org/2001/XMLSchema-instance](http://www.w3.org/2001/XMLSchema-instance)">
<!-- Represents maximum allowed connections -->
<max_conn>10</max_conn>
<!-- Maximum number of threads that the product is allowed to use -->
<max_threads>100</max_threads>
<!-- Default port to connect to -->
<port>3306</port>
</configuration>
Not exactly easy for us to read, right? Though XML compromises on human-readability it comes with its advantages as we saw earlier.
Introduce methods for XML file type in the Config Manager class
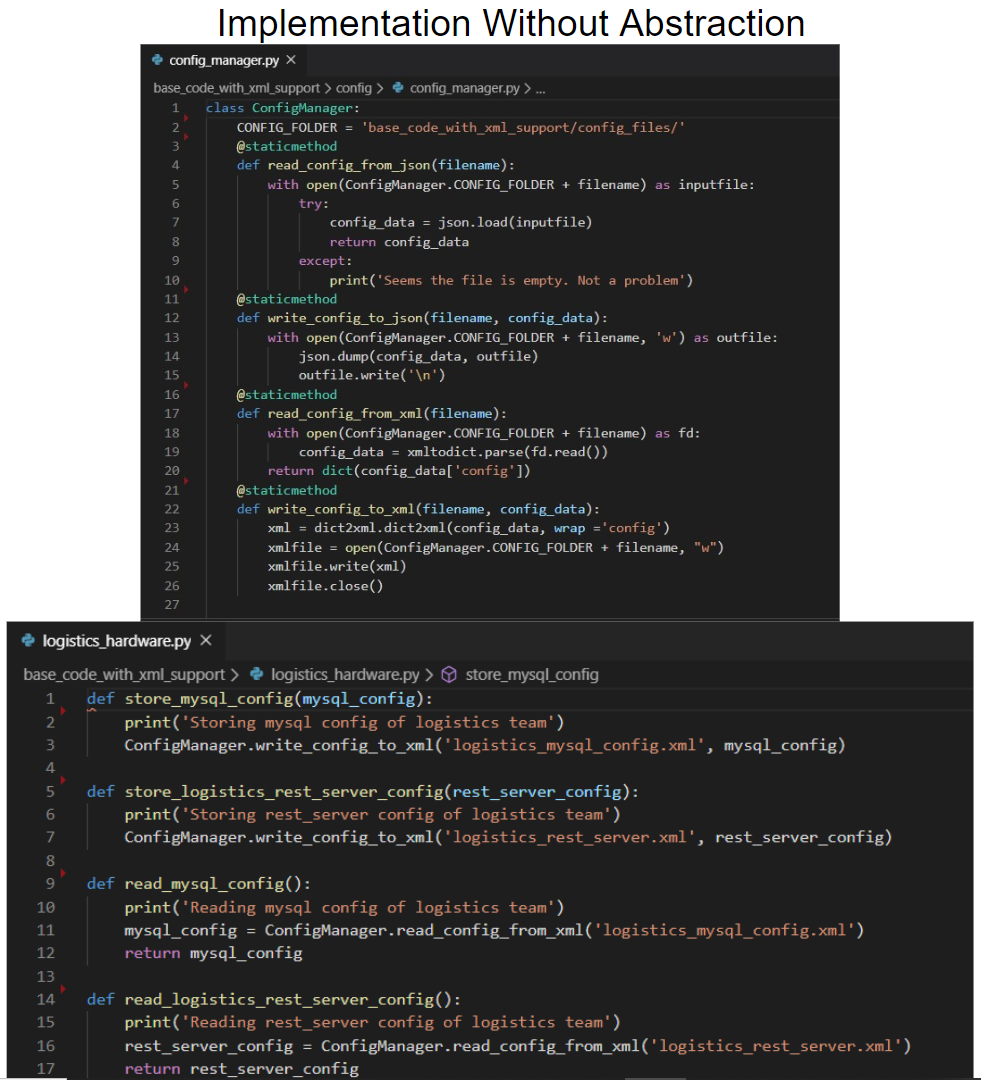
One way to implement XML support is to add new methods to read & write XML configuration files inside our ConfigManager class. Teams can then utilize these methods.
This version can be found inside the base_code_with_xml_support/ directory
If we look inside base_code_with_xml_support/config/config_manager.py, there are two new methods
@staticmethod
def read_config_from_xml(filename):
with open(ConfigManager.CONFIG_FOLDER + filename) as fd:
config_data = xmltodict.parse(fd.read())
return dict(config_data['config'])
@staticmethod
def write_config_to_xml(filename, config_data):
xml = dict2xml.dict2xml(config_data, wrap ='config')
xmlfile = open(ConfigManager.CONFIG_FOLDER + filename, "w")
xmlfile.write(xml)
xmlfile.close()
The earlier implementation for dealing with JSON configuration is now renamed to read_config_from_json() from read_config. Similarly, for the write method as well.
The Logistics team has shifted to XML based configuration, while the Inventory and Vendor teams stay with JSON.
Let’s also check how the implementation of the Logistics team changed in base_code_with_xml_support/logistics_hardware.py.
def store_logistics_rest_server_config(rest_server_config):
print('Storing rest_server config of logistics team')
ConfigManager.write_config_to_xml('logistics_rest_server.xml', rest_server_config)
def read_logistics_rest_server_config():
print('Reading rest_server config of logistics team')
rest_server_config = ConfigManager.read_config_from_xml('logistics_rest_server.xml')
return rest_server_config
Ok, they had to change their original implementation by modifying the method names and parameters at multiple places.
Try running the base_code_with_xml_support/main.py file
python3 base_code_with_xml_support/main.py
Compare the contents of base_code_with_xml_support/config_files/logistics_rest_server.xml file, that was just created with the base_code/config_files/logistics_rest_server.json file from our earlier implementation. Same configuration, different format, right?
Drawbacks
The above design works but has some disadvantages.
-
Adding support for another file type will involve creating even more methods in config_manager.py, making it cluttered. For now, we have renamed previous methods and added two new methods.
-
The Clients using this code need to make corresponding changes to method names and parameter values, which might be getting invoked in multiple places.
Why should we think about Abstraction here?
With the implementation in the previous milestone, we see that new methods were put into the config_manager class. This keeps the implementation in one place. However, with more and more methods being added, the config_manager is catering to multiple use cases which are better off in their own class. Having their own class will make it easier to maintain and have clear responsibilities.
Also, the users explicitly need to use method names based on the file type and are no longer generic. If they are making this call in multiple places, users would need to replace all occurrences, if they need to change the file type.
Abstraction addresses these shortcomings by clearly defining a common method signature. Separate classes can implement the same method but internally read the file type of choice. From a user perspective, the methods don’t change based on file type and it is easy to change from one type to another with minimal changes.
How to apply Abstraction?
Let’s go through an Abstraction driven design for this requirement to see how it is better.
Redesigned Code
We had a couple of shortcomings:
-
ConfigManagerclass is catering to multiple use cases -
Method names in
ConfigManagerare to be changed in all places they’re used.
This redesigned version can be found inside the oop_way/ directory.
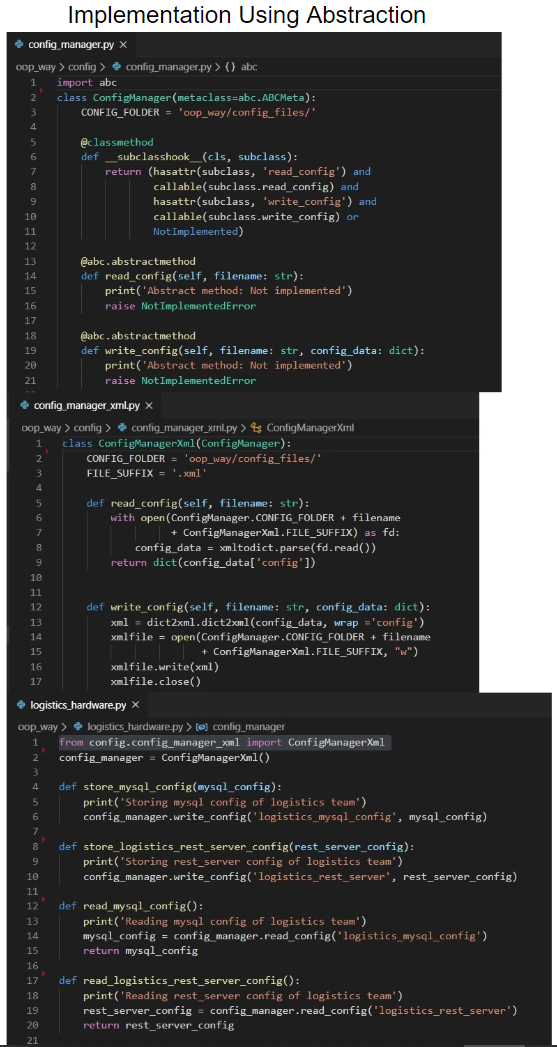
To combat the first issue, we go with an abstract class ConfigManager inside oop_way/config/config_manager.py. Abstract class? Yeah, we won’t provide any implementation in this class, just the method names. Other classes will then implement these methods based on the file types they need to support.
@abc.abstractmethod
def read_config(self, filename: str):
print('Abstract method: Not implemented')
raise NotImplementedError
@abc.abstractmethod
def write_config(self, filename: str, config_data: dict):
print('Abstract method: Not implemented')
raise NotImplementedError
Let’s look at what the method definitions are trying to say
-
read_config(self, filename: str)- sets an abstract methodread_configwhich takes a single parameter,filenamedenoting the configuration file name. No,selfisn’t another parameter but just denotes object of theConfigManagerclass itself -
write_config(self, filename: str, config_data: dict)- defines the abstract methodwrite_configwhich takes two parameters, configuration file name & the configuration data to be written to the config file.
Now, the fancy annotation @abc.abstractmethod along with the __subclasshook__() method is required as Python doesn’t support abstract classes by default.
@classmethod
def __subclasshook__(cls, subclass):
return (hasattr(subclass, 'read_config') and
callable(subclass.read_config) and
hasattr(subclass, 'write_config') and
callable(subclass.write_config) or
NotImplemented)
Now we have the method signature required for reading & writing configuration laid out clearly. Each configuration file type can be supported by a subclass of the ConfigManager class which will implement the specific read/write functionality of that type.
You can see that we have a class each for dealing with the JSON & XML configurations. Let’s check the oop_way/config/config_manager_json.py file.
class ConfigManagerJson(ConfigManager):
CONFIG_FOLDER = 'oop_way/config_files/'
FILE_SUFFIX = '.json'
def read_config(self, filename: str):
with open(ConfigManager.CONFIG_FOLDER + filename
+ ConfigManagerJson.FILE_SUFFIX) as inputfile:
try:
config_data = json.load(inputfile)
return config_data
except:
print('Seems the file is empty. Not a problem')
def write_config(self, filename: str, config_data: dict):
with open(ConfigManager.CONFIG_FOLDER + filename
+ ConfigManagerJson.FILE_SUFFIX, 'w') as outfile:
json.dump(config_data, outfile)
outfile.write('\n')
Some points we can comprehend from the code
-
The
ConfigManagerJsonclass is a subclass of theConfigManagerabstract class -
It implements both of the abstract methods defined in
ConfigManager
Similarly, we have the implementation for the XML type configuration in oop_way/config/config_manager_xml.py
All done, right? Hmm, Not really!
Our earlier implementation had one more drawback - we were dealing with the issue of having to change method names and parameter values in all previous implementations, whenever support for a new config file type was added. This made the code harder to maintain.
How did we deal with this in our new implementation based on Abstraction?
Taking a look at the Logistics team’s implementation in oop_way/logistics_hardware.py
config_manager = ConfigManagerXml()
def store_mysql_config(mysql_config):
print('Storing mysql config of logistics team')
config_manager.write_config('logistics_mysql_config', mysql_config)
def store_logistics_rest_server_config(rest_server_config):
print('Storing rest_server config of logistics team')
config_manager.write_config('logistics_rest_server', rest_server_config)
def read_mysql_config():
print('Reading mysql config of logistics team')
mysql_config = config_manager.read_config('logistics_mysql_config')
return mysql_config
def read_logistics_rest_server_config():
print('Reading rest_server config of logistics team')
rest_server_config = config_manager.read_config('logistics_rest_server')
return rest_server_config
As the Logistics team moved to using XML, they are creating an object of the ConfigManagerXml() class and it’s methods for reading & writing configuration as XML type.
What would the Logistics team need to do if they were having second thoughts to go back to JSON itself? They’d need to just change config_manager to an object of type ConfigManagerJson instead of ConfigManagerXml. Done!
You can use the below command for running oop_way/main.py
python3 oop_way/main.py
Additional Enhancement
New requirements have come in, to add support for storing configuration in CSV files and also in a Database.
How easy or difficult is it (with the abstraction based design) to add this support?
Debrief
-
Practical scenarios
-
The Java Virtual Machine is an abstraction. Your code can use the exact same java methods irrespective of whether your code will run on Linux or Windows or any other OS. Underneath, a lot of things will change depending on the OS, which the user doesn’t need to know.
-
You can use a simple API call to fetch weather data or stock prices. These API abstract out the internal complexities of how it is implemented.
-
Software libraries are good examples of abstraction. They tell you the methods you can use without telling you how they are implemented.
-
-
Summary of Abstraction
-
It separates the method signature from its implementation.
-
Closely related classes can separate out common fields/methods into a different class and reuse that class.
-
Why is it useful? - To the implementers of the class, it is useful since it provides them with the flexibility to change things as long as the method signatures don’t change. For the users, it keeps them from getting exposed to anything other than the method signatures they need to know, reducing complexity.
-
How to apply? - Use a smaller set of public methods
-
What is the drawback if we don’t use abstraction? - Low maintainability because responsibilities are not clearly differentiated. Higher Complexity with larger code bases because many objects interact with others and it becomes difficult to add functionality without impacting others.
-
-
Language specific notes
-
In Java,
interfaceclasses provides total abstraction andabstractclasses provide partial abstraction -
Python interface can be applied as shown in this Byte
-
In C++, you can use either header files to achieve abstraction or private methods to hide implementation details.
-
-
General Abstraction notes
-
Hides underlying complexity of data from users
-
Helps avoid repetitive code
-
Presents only the signature of internal functionality
-
Gives flexibility to programmers to change the implementation of the abstract behaviour
-
-
Difference between Encapsulation and Abstraction
-
Abstraction is a natural extension of Encapsulation. Encapsulation recommends that you create entities/objects which contain closely related fields and functionality/methods. Abstraction further recommends that the entities expose only their method signatures to external users who shouldn’t need to worry about the underlying implementation.
-
Encapsulation - hide data. Abstraction - hide complexity.
-
Curious Cats
-
What is the difference between a regular class, an abstract class and an interface class in Java?
-
How can you spot if a code base has used Abstraction in its design?
-
What happens if we don't use the
@abc.abstractmethodannotation & the_subclasshook_ method()method in ourConfigManagerclass? Comment outread_config()implementation inconfig_manager_json.py. Try running th oops/main.py method before and after commenting out theabc.abstractmethodannotation & the_subclasshook_()method
Newfound Superpowers
- You are now cruising along the Abstraction Understood highway, ready to design larger pieces of software more efficiently.
Now you can
-
Think about the bigger picture with situations where abstraction adds value.
-
Crack that interview question with a real example
-
Answer these interview questions
-
What is Abstraction?
-
What is the difference between Encapsulation and Abstraction?
-