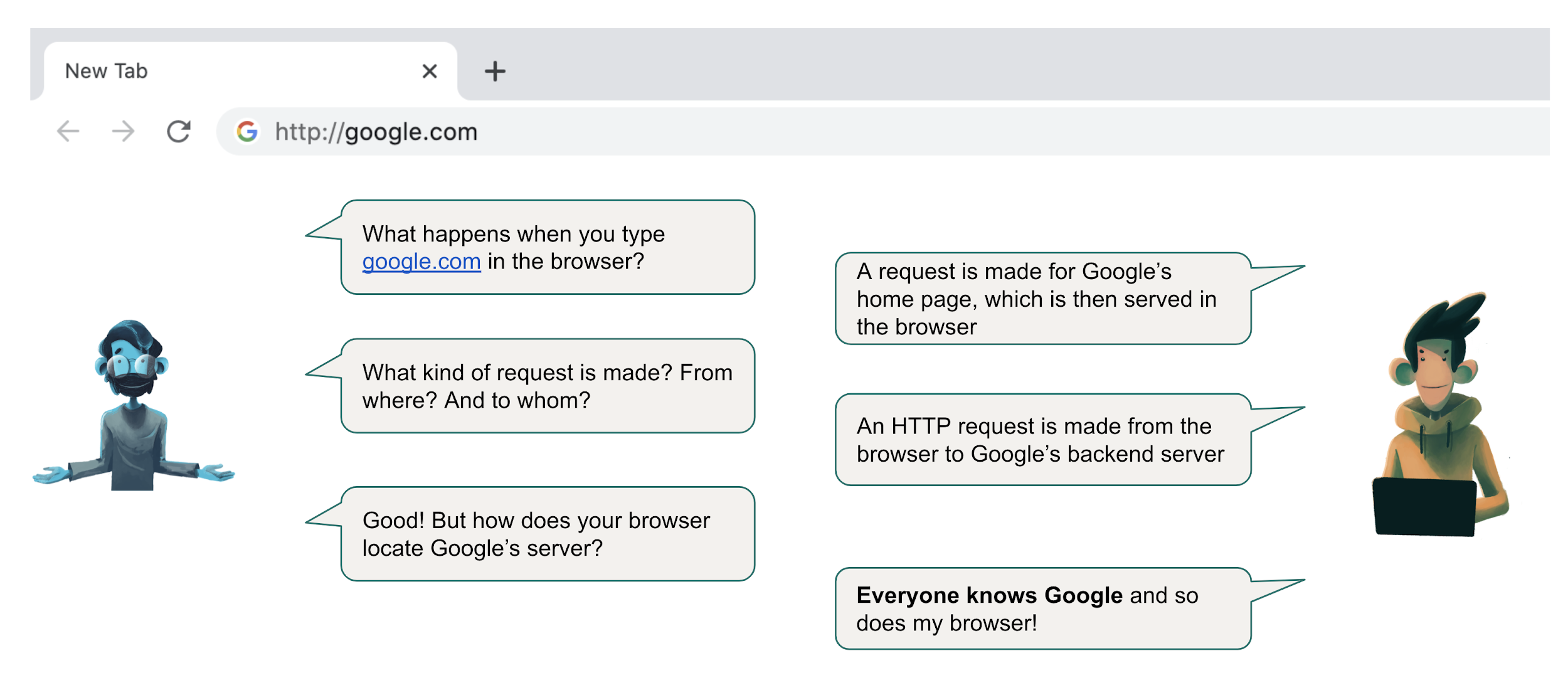
Does the above interview sound familiar? Typically "What happens when you type google.com" is a wide open question where a wide variety of concepts can be touched upon.
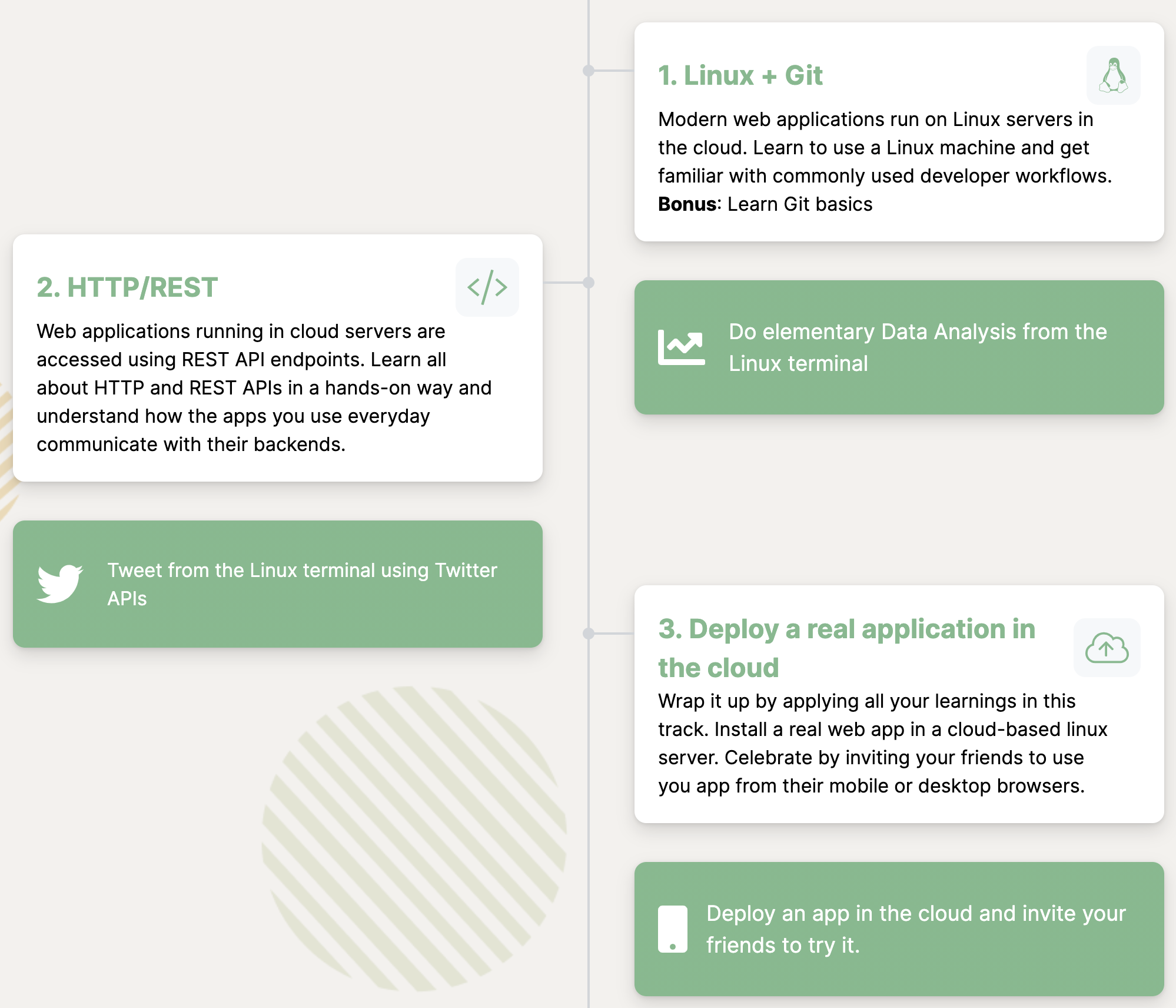
The discussion can touch upon:
-
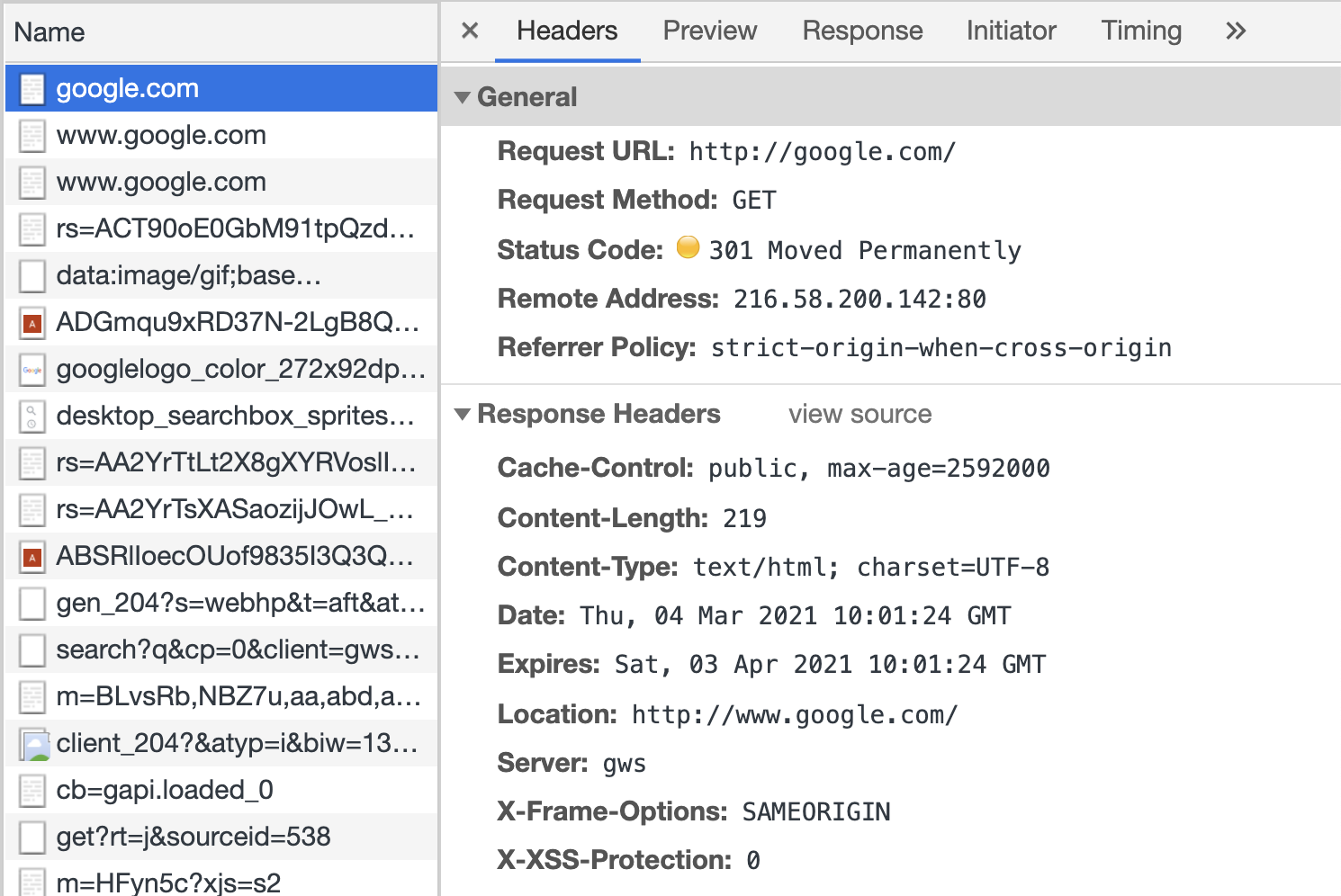
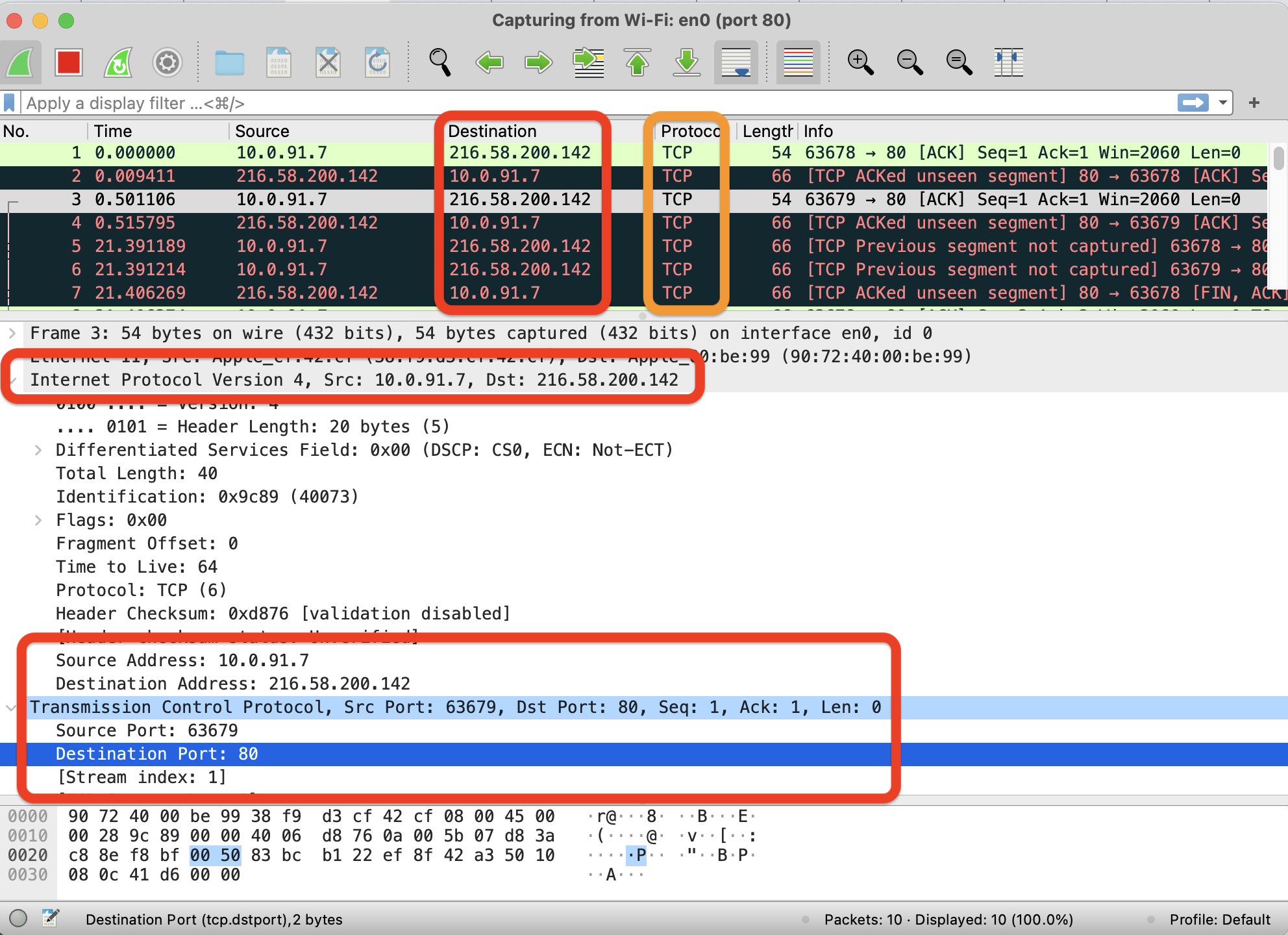
HTTP vs HTTPS and their respective port numbers
-
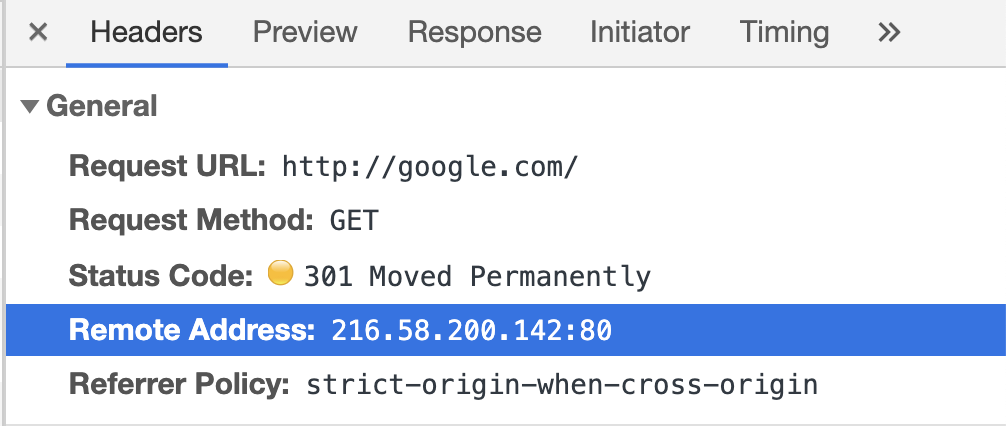
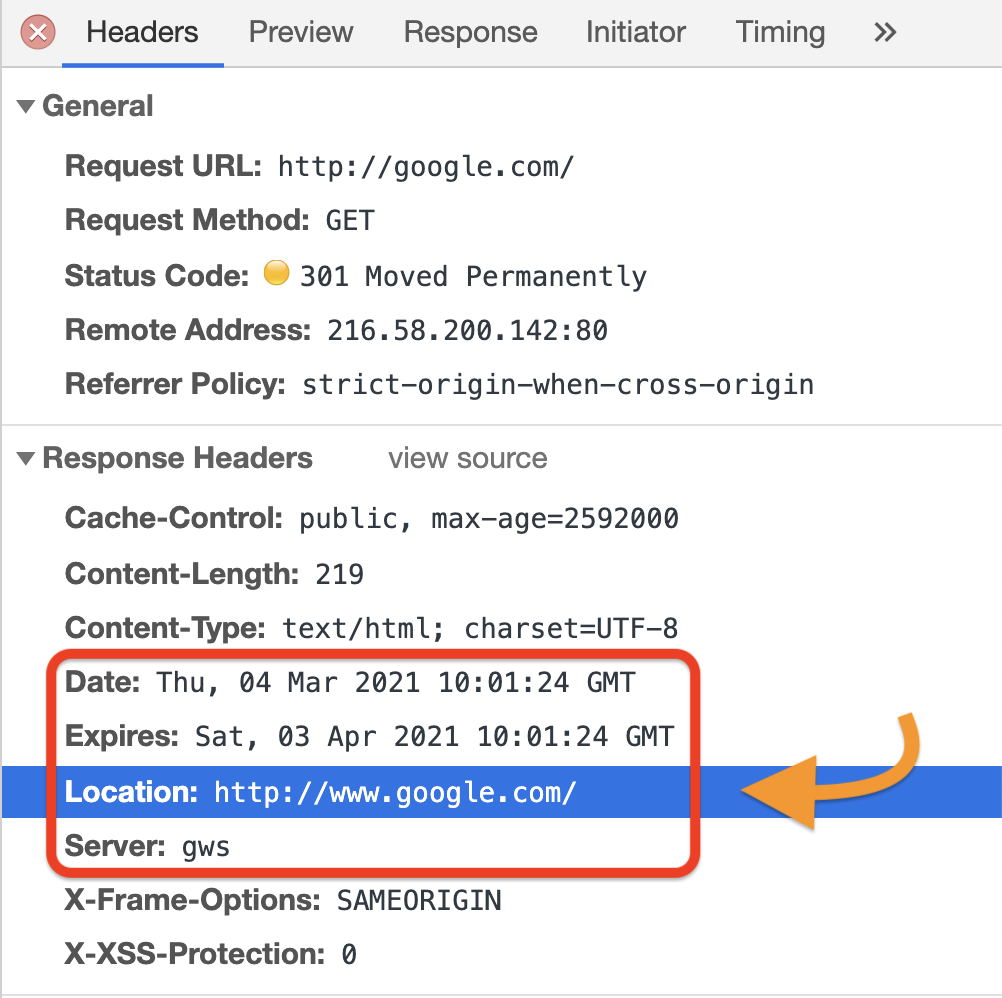
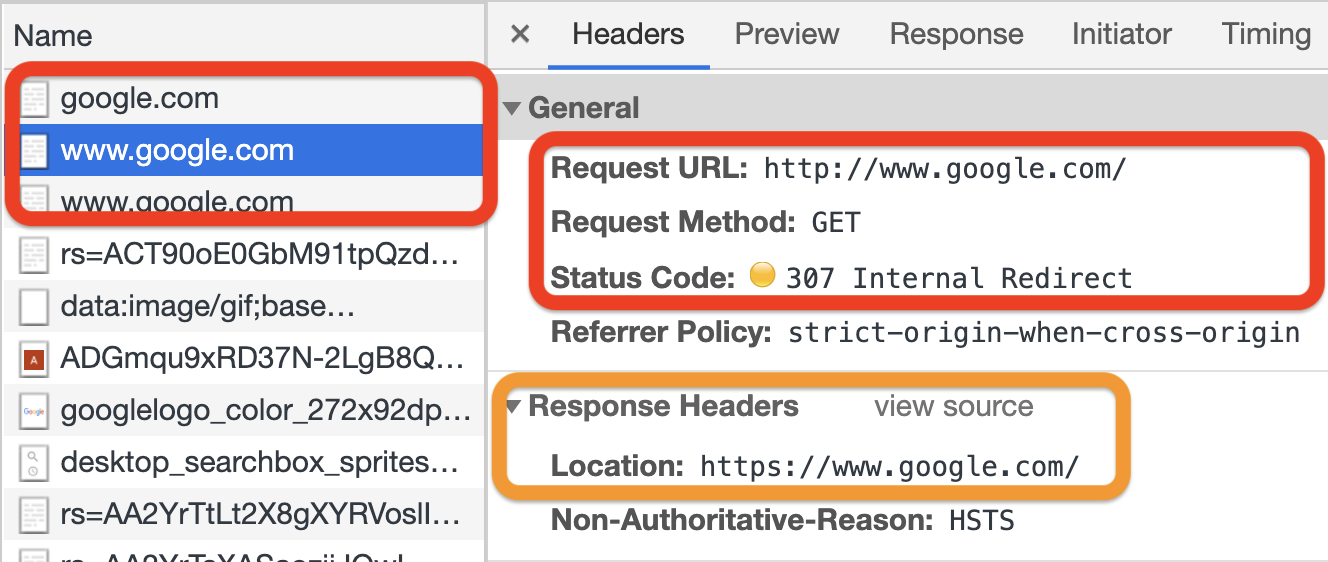
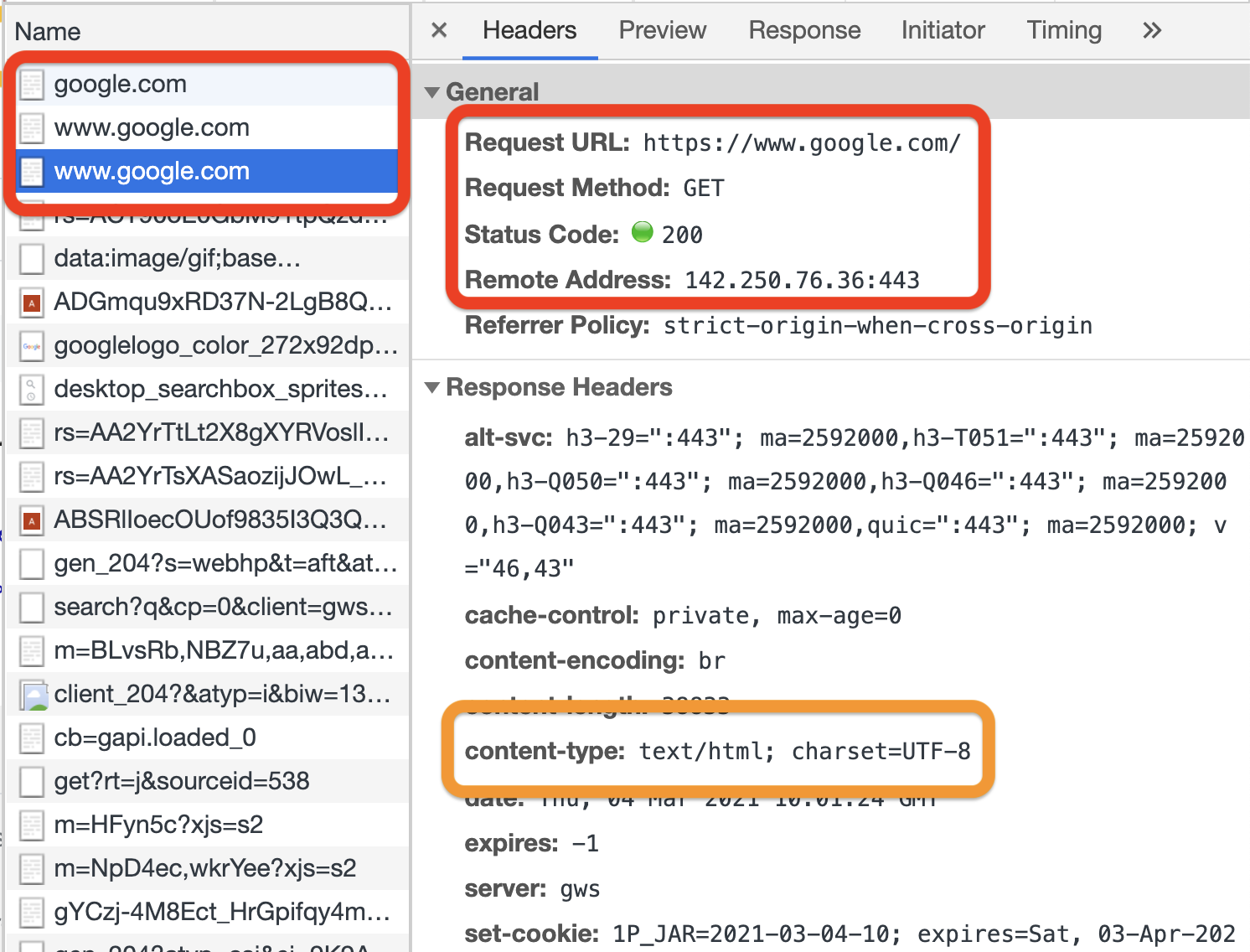
HTTP redirects, responses and status codes
-
HTTP methods and RESTful web services
-
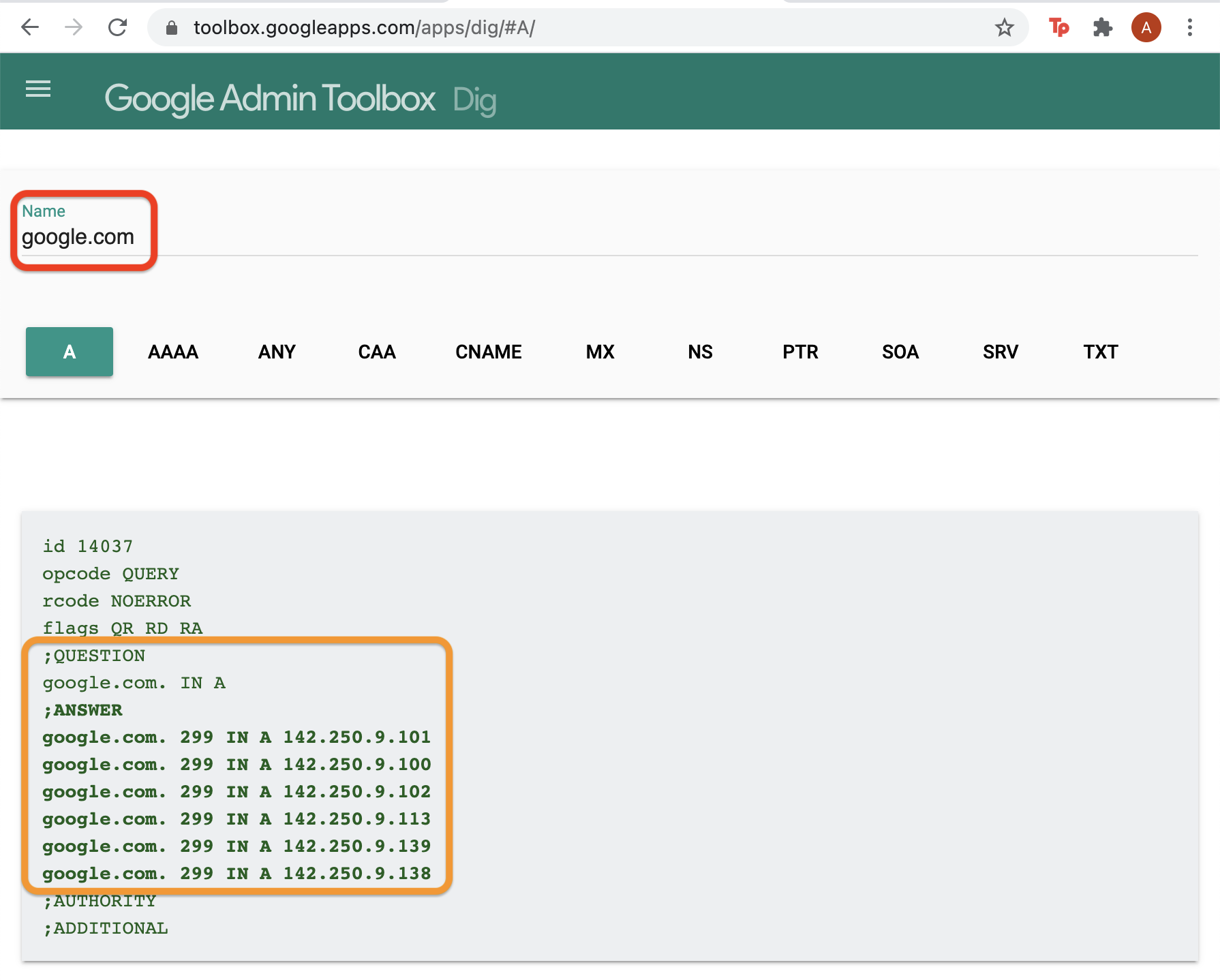
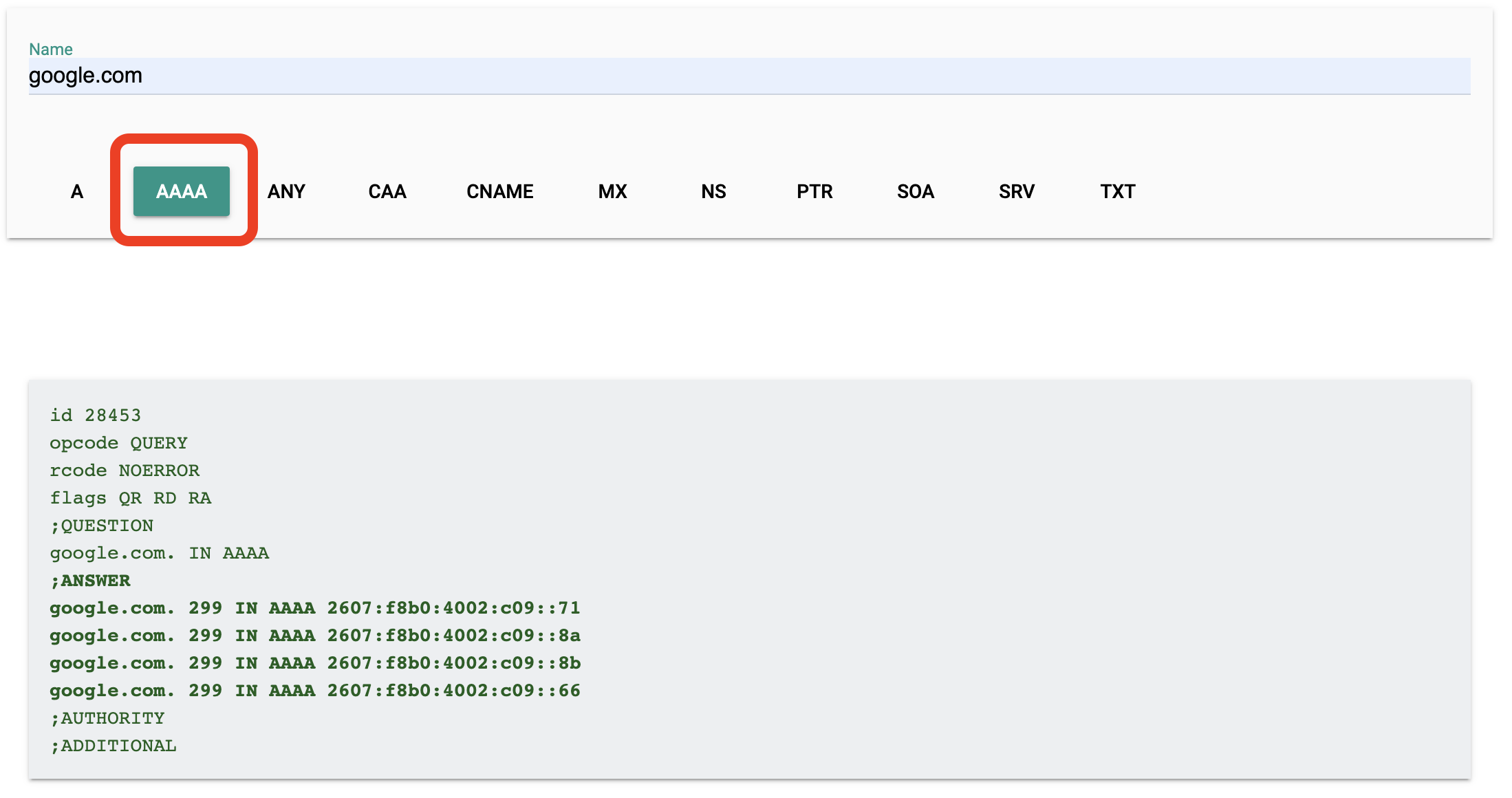
DNS, load balancing
-
and more..
The more detailed your answer => the better your interview performance. The question is: how do you prepare to answer this question in detail?
Let’s find out - the Crio way.
I hear and I forget
I see and I remember
I do and I understand