You will be reading data from CSV files and transforming data to generate final output tables to be stored in traditional DBMS.
Objective
Project Context
We have New York Yellow taxi trip dataset available with us and let us assume that the client wants to see the analysis of the overall data. Now, the size of the dataset is very huge (might go up to billions of rows) and using traditional DBMS is not feasible. So, we will use Big Data tool like Apache Spark to transform the data and generate the necessary aggregated output tables and store it in MySQL database. With this architecture the UI will be able to fetch reports and charts at much faster speed from MySQL than querying on the actual raw data.
Finally, the batch we use to analyze the data can be automated to run on daily basis within a fixed period of time.
Project Stages
The project consists of the following stages:

High-Level Approach
-
Setup the environment and install all the tools required for the project.

-
Read data from CSV file and store the data into HDFS (Hadoop File System) in compressed format.

-
Transform the raw data and build multiple table by performing the required aggregations.
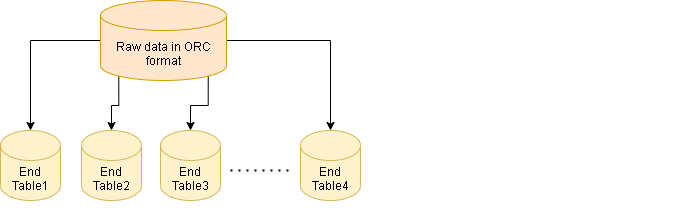
-
Load the end tables to MySQL tables.
-
Automating the full flow using Shell Script.
The video below provides the overview of the project.
Primary goals
- Transform the raw data into multiple tables as per the requirement.
- Load the tables to MySQL.
- Automate the flow so it can be scheduled to be ran on a regular basis.
Objective
You will be reading data from CSV files and transforming data to generate final output tables to be stored in traditional DBMS.
Project Context
We have New York Yellow taxi trip dataset available with us and let us assume that the client wants to see the analysis of the overall data. Now, the size of the dataset is very huge (might go up to billions of rows) and using traditional DBMS is not feasible. So, we will use Big Data tool like Apache Spark to transform the data and generate the necessary aggregated output tables and store it in MySQL database. With this architecture the UI will be able to fetch reports and charts at much faster speed from MySQL than querying on the actual raw data.
Finally, the batch we use to analyze the data can be automated to run on daily basis within a fixed period of time.
Project Stages
The project consists of the following stages:
High-Level Approach
-
Setup the environment and install all the tools required for the project.
-
Read data from CSV file and store the data into HDFS (Hadoop File System) in compressed format.
-
Transform the raw data and build multiple table by performing the required aggregations.
-
Load the end tables to MySQL tables.
-
Automating the full flow using Shell Script.
The video below provides the overview of the project.
Primary goals
- Transform the raw data into multiple tables as per the requirement.
- Load the tables to MySQL.
- Automate the flow so it can be scheduled to be ran on a regular basis.
Setting up the environment
The first task for us to begin with our project is to setup our system environment.
Requirements
-
It is expected that you are using a Linux distribution. (A cloud system can be a substitute.)
-
We have to install all the tools and setup the environment (if you have already installed the required tools you can skip this task), make sure you install all the required software in one location for simplicity.
-
Install Hadoop in your system using this tutorial.
-
Once Hadoop is set up, start the services using
start-all.shcommand and runjpsto check whether the services are up or not. Below screenshot shows the expected services that should be running on successful installation.
-
Now, you can install Apache Spark using this link
-
Once spark is installed we will install Anaconda. Download Anaconda bash installer file from Anaconda website. Install and initialize it.
-
Finally install MySQL.
-
Now, by default Spark is supposed to start on terminal, to use Jupyter Notebook for development we will have to set some properties in ~/.bashrc file.
- export PYSPARK_DRIVER_PYTHON=jupyter
- export PYSPARK_DRIVER_PYTHON_OPTS='notebook'
-
Finally, you can run
pysparkcommand in terminal which should start Spark on Jupyter Notebook.
Bring it On!
- Try to initialize Spark UI and check out where it is running.
- Give alias to initialize Spark services in '~/.bashrc' file using you own command.
Expected Outcome
The main objective of this milestone is to make sure that you have all the software set up in your Linux distro. On successful completion of the milestone you should have your Jupyter notebook running and all the Hadoop services running in your machine.
Downloading the dataset
Download the NYC Yellow Taxi dataset from its website. The dataset is huge and contains almost 80-90 Million records for each year. So, you can go ahead and download one year's dataset for the project. The dataset would be in CSV format.
Requirements
- Once you have the dataset in your local system, load it to HDFS using Pyspark.
- Make sure you use Jupyter Notebook to load the data from Local File system to HDFS and the output format in which data is stored in HDFS is in ORC format.
Bring it On!
- Explore the various types of compression techniques in HDFS and try to save the data in any format apart from ORC and check whether the read/write is getting any better.
Expected Outcome
When you are done with this milestone, it is expected that you should have the dataset in compressed file format in Hadoop file system.
Set up Payments OTC table
-
You will need Payments mapping table for certain analysis, you can set it up by running below commands in mysql.
-
Initialize MySQL.
-
Commands:
create database source; use source; create table payment_otc(payment_type int NOT NULL, payment_name varchar(255) NOT NULL); INSERT INTO payment_otc VALUES(1, 'Cash'); INSERT INTO payment_otc VALUES(2, 'Net Banking'); INSERT INTO payment_otc VALUES(3, 'UPI'); INSERT INTO payment_otc VALUES(4, 'Net Banking'); INSERT INTO payment_otc VALUES(5, 'Debit Card');
Requirements
- Make sure you create a new script for the transformations and not use the same one you made for copying files from Local file system to HDFS.
- Read the dataset stored in HDFS into Spark Dataframe.
- You should have data like this:
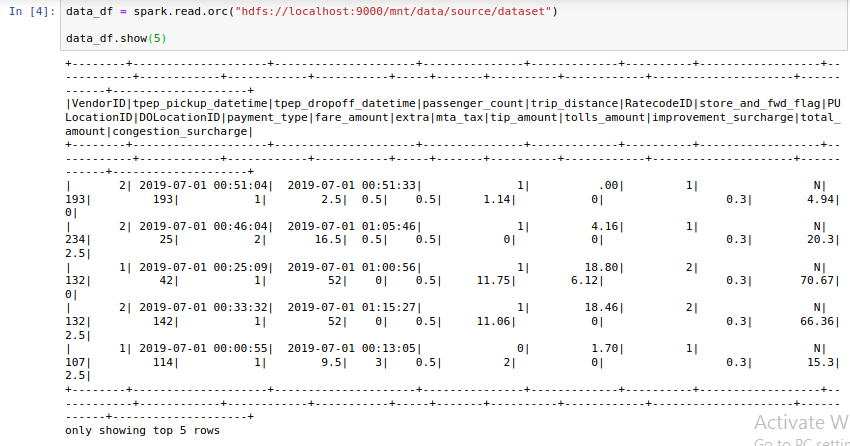
- Perform below mentioned analysis:
- Week level aggregation of Sales of each vendor
- Month level aggregation of Sales of each vendor
- Average amount of congestion surcharge each vendor charged in each month
- Distribution of percentage of trips at each hour of day
- Top 3 payment types users used in each month (make sure you get payment_name information for payments table in MySQL)
- Distribution of payment type in each month
- Total passengers each Vendor served in each month
- Use
tpep_pickup_datetimecolumn whenever date information is needed. - Make sure you store the final output dataframes back to HDFS.
References
Expected Outcome
- One successful completion of this milestone you should have all the seven tables (or files) in ORC format in HDFS.
- You can check the files in HDFS as given below:

Loading Data to MySQL
In this milestone, we will load the data from HDFS file system to Mysql.
Requirements
- This task should be done using Pyspark as well.
- Initially download mysql jdbc jar required to load data from spark to MySQL.
- Initialize jupyter notebook by specifying mysql jar.
- Create a script that will read data from HDFS and load it to MySQL.
Expected Outcome
At the end of the milestone you should have all the seven tables in MySQL. You can verify by querying and checking the data in MySQL.
Curious Cats
- Without creating table in MySQL how was Spark able to write directly to MySQL?
- How are the datatypes in MySQL assigned to each column when Spark write data to MySQL table?
- If we already have existing table in MySQL will Spark change its structure or schema while performing write operations?
Automation of flow using Shell Script
Who doesn't like automation? This milestone is all about it, where we'll be automating all our previous manual effort.
Requirements
In this milestone, we will automate the flow using Shell Script.
- Convert the scripts from IPython Notebook format to Python format.
- Try submitting one sample spark script using spark-submit command. Make sure
--masterargument is given Spark Master URL. - Now, create a shell script which will run all the scripts in sequence.
- Try executing the shell script and monitor the job on Spark Master URL.
- Schedule the script using Cron Tab which is supposed to run regularly at a certain time.
Expected Outcome
At the end of the milestone you will be having a shell script which will running the full batch at a certain time. You should be able to monitor the Spark jobs on Spark UI.
Things to Explore
- Explore the various scheduling tools that are used normally for Big Data Projects.
- Try performing the same analysis for more number of years.
- Explore Spark Interview questions.
- How do you perform delta operations in pyspark?