You will implement a Command Line Interface (CLI) which will preprocess your dataset and save your time.
Objective
Project Context
Machine Learning is a subset of the larger field of artificial intelligence (AI) that focuses on teaching computers how to learn without the need to be programmed for specific tasks. In fact, the key idea behind ML is that it is possible to create algorithms that learn from and make predictions on the data.
Examples of Machine Learning are present everywhere including the spam filter that flags messages in your email, the recommendation engine Netflix uses to suggest content you might like, and the self-driving cars being developed by Google and other companies.
But before applying Machine Learning on any dataset, you need to convert it in such a way that the algorithms could understand the dataset. These steps are preprocessing steps.
To know more about preprocessing, refer to this article.
Data preprocessing is an integral step in Machine Learning as the quality of data and the useful information that can be derived from it directly affects the ability of your model to learn; therefore, it is extremely crucial that you preprocess your data before feeding it into your model.
One more advantage of preprocessing is that it is considered time consuming for many machine learning developers. This simple CLI tool will save your time so that you can utilize it in applying different machine learning algorithms.
You will apply the following preprocessing steps:
- Handling NULL values
- Encoding Categorical Data
- Feature Scaling
To understand different preprocessing steps, refer to this article.
Finally, you will also be able to download your preprocessed dataset.
Product Architecture
The Product Architecture consists of 6 parts which are as follows:

High-level approach
This project consists of the following milestones:
- Input the Dataset
- Data Description
- Handling NULL Values
- Encoding Categorical Data
- Feature Scaling
- Download the preprocessed Dataset
Pandas and scikit learn will be used throughout the project to perform the preprocessig steps.
The desired end result of this project is like this:
Objective
You will implement a Command Line Interface (CLI) which will preprocess your dataset and save your time.
Project Context
Machine Learning is a subset of the larger field of artificial intelligence (AI) that focuses on teaching computers how to learn without the need to be programmed for specific tasks. In fact, the key idea behind ML is that it is possible to create algorithms that learn from and make predictions on the data.
Examples of Machine Learning are present everywhere including the spam filter that flags messages in your email, the recommendation engine Netflix uses to suggest content you might like, and the self-driving cars being developed by Google and other companies.
But before applying Machine Learning on any dataset, you need to convert it in such a way that the algorithms could understand the dataset. These steps are preprocessing steps.
To know more about preprocessing, refer to this article.
Data preprocessing is an integral step in Machine Learning as the quality of data and the useful information that can be derived from it directly affects the ability of your model to learn; therefore, it is extremely crucial that you preprocess your data before feeding it into your model.
One more advantage of preprocessing is that it is considered time consuming for many machine learning developers. This simple CLI tool will save your time so that you can utilize it in applying different machine learning algorithms.
You will apply the following preprocessing steps:
- Handling NULL values
- Encoding Categorical Data
- Feature Scaling
To understand different preprocessing steps, refer to this article.
Finally, you will also be able to download your preprocessed dataset.
Product Architecture
The Product Architecture consists of 6 parts which are as follows:
High-level approach
This project consists of the following milestones:
- Input the Dataset
- Data Description
- Handling NULL Values
- Encoding Categorical Data
- Feature Scaling
- Download the preprocessed Dataset
Pandas and scikit learn will be used throughout the project to perform the preprocessig steps.
The desired end result of this project is like this:
Input the Dataset
There are several types of Machine Learning such as Supervised learning, Unsupervised learning etc. Here, you are writing python scripts to make preprocessed dataset for performing supervised learning.
Supervised learning consists of mapping input data (independent variables) to known targets (dependent variable), which humans have provided. Predicting house prices is a good example.
Important: For simultaneously testing out our application you will be performing the preprocessing on a very popular ML dataset - Titanic survival Dataset. You need to download train.csv dataset from the mentioned website.
The idea of this milestone is that you are correctly taking the input of the dataset.
Requirements
- This is a python application and the project structure is shown below.
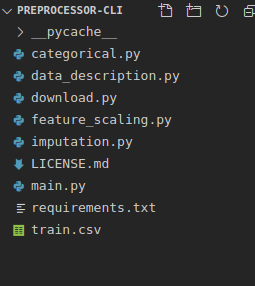
- Make a main class for the Project where all below functions will be defined -
- A function that only takes a ‘.csv’ input from the command line.
- A function that chooses a target (dependent) variable and removes it from the dataset, so that you can start preprocessing on all the independent variables.
- Each task will have a separate class and will be called by their respective object.
- Handle all the exceptions in the input.
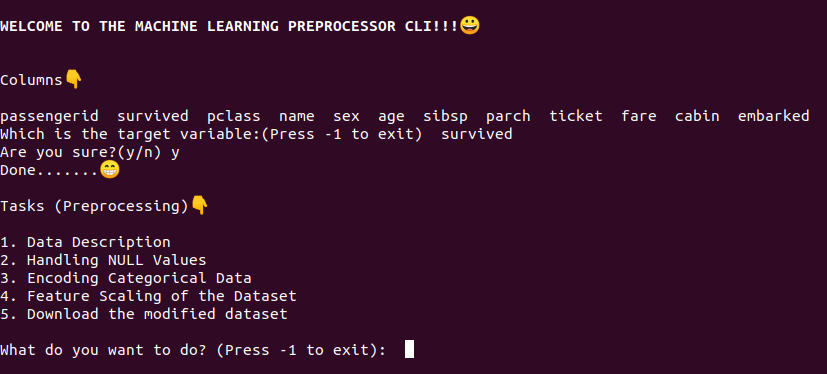
Expected Outcome
At the end of this milestone, the project should work like this.
Data Description
Now that you are done with the initial step, you can implement various components of your project.
In this milestone, you need to implement the functionality that will enable users to describe the dataset’s properties like mean, max, standard deviation etc.
The idea of this milestone is that you can correctly show some basic statistical details (mean, standard deviation, percentiles, total number of values, maximum, minimum), datatype of columns of the dataset using methods provided by pandas library.
Requirements
- Make a separate class for Data Description where all below functions will be defined -
- A function that shows properties (mean, standard deviation, percentiles, total number of values, maximum, minimum) of each numeric column. This function should also show the datatypes along with the null value count of each column.
- A function that shows the property of any specific column.
- A numeric column should show properties like mean, standard deviation, percentiles, total number of values, maximum and minimum.
- A string column should show properties like total number of values and number of distinct values.
- A function that takes a number of rows ‘n’ as input and prints the dataset.
- Handle all the exceptions in the input.
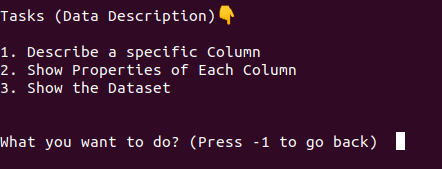
Expected Outcome
At the end of this milestone, the project should work like this.
Handling NULL Values
The next step of data preprocessing is to handle missing data in the datasets. If your dataset contains some missing data, then it may create a huge problem for your machine learning model. Hence it is necessary to handle missing values present in the dataset.
The handling of missing values is also called Data Imputation.
The idea of this milestone is to remove all the NULL values from the dataset.
Requirements
- Make a separate class for Data Imputation where all below functions will be defined -
- A function that removes the specified column.
- Three respective functions that fill the null values in a column with mean, median and mode.
- Handle all the exceptions in the input.
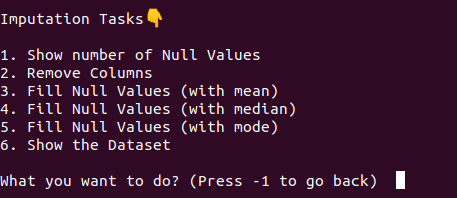
Expected Outcome
At the end of this milestone, the project should work like this.
Encoding Categorical Data
Categorical data is data which has some categories. Machine learning models completely works on mathematics and numbers, but if your dataset would have a categorical variable, then it may create trouble while building the model. So, it is necessary to encode these categorical variables into numbers.
The idea of this milestone is to map all the categorical columns into numbers.
Requirements
- Make a separate class for Encoding Categorical data where all below functions will be defined -
- A function that shows all the Categorical columns present in the dataset
- A function that performs one hot encoding for a categorical column.
- Handle all the exceptions in the input.
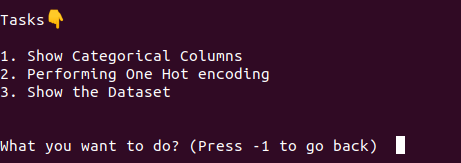
Expected Outcome
At the end of this milestone, the project should work like this.
Feature Scaling
Feature scaling is a method used to normalize the range of independent variables or columns of data. It is done to handle highly varying magnitudes among different columns.
If feature scaling is not done, then a machine learning algorithm tends to weigh greater values, higher and consider smaller values as the lower values, regardless of the unit of the values. To avoid this, feature scaling is done.
There are 2 main ways of doing feature scaling:
- Normalization
- Standardization
The idea of this milestone is that you are able to correctly scale the dataset.
Requirements
- Make a separate class for Feature Scaling where all below functions will be defined -
- A function that performs normalization of any specific column or group of columns.
- A function that performs standardization of any specific column or group of columns.
- Handle all the exceptions in the input.

Expected Outcome
At the end of this milestone, the project should work like this.
Download the dataset
As all the preprocessing is done, you can implement the functionality to download the preprocessed dataset.
The idea of this milestone is that you can correctly download the dataset in the correct file format.
Requirements
- Make a separate class for Downloading the dataset where below function will be defined -
- A function that downloads the preprocessed dataset with the provided name.
- Handle all the exceptions in the input.

References
Expected Outcome
At the end of this milestone, the project should work like this.