
Before you begin...
Did you know that most of the mobile apps you use every day uses JSON to talk to the backend? Before you dive deep into the basics of this popularly used structured format, let's find out how much you know about JSON.
Take Quiz To Find Out!JavaScript Object Notation (full form of JSON) is a standard file format used to interchange data. The data objects are stored and transmitted using key-value pairs and array data types. In simpler terms, JSON data is (in some ways) the language of databases.
JSON has syntactic similarity to JavaScript because JSON is based on JavaScript object notation syntaxes. But JSON format is text only, which makes it easy to read and use with any programming language. This blog will introduce you to everything there is to know of JSON like:
- Where is JSON used?
- Why JSON?
- JSON vs XML
- JSON syntaxes and data types
- Working of JSON
- JSON and REST APIs
- JSON and JavaScript
- Practical applications of JSON
So, dive in right away!
Where is JSON used?
JSON data format is ubiquitous in web APIs, cloud computing, NoSQL databases (like MongoDB), and increasingly also in Machine Learning.
This is how a typical JSON data looks like (more on this in upcoming sections) -
{
"_id": "5c8a1d5b0190b214360dc097",
"category": “Crio Bytes",
"clusterName": "OOP Foundations",
"bytes": [“Abstraction”, “Inheritance”, “Encapsulation”, “Polymorphism”]
"isFree": true
}More generic scenarios where JSON data format is used are:
- Data storage, configuration, and validation
- Data transfer between APIs, client, and server
- Restructuring input data from the user (JSON schema)
Data storage, configuration, and validation
You might be familiar with the package.json files in your node (specifically NPM) projects. This is a configuration file for your project which holds important metadata. Also, JSON files can be used to store tons of data that you may need to use within your project itself. Think of it as an internal mini-database for text-only data. Refer to the two photos below for the two cases I explained (respectively). JSON plays a very critical role in validation, as in via JWT (JSON Web Token), which is a method of securely transmitting digital information between two parties. Think of it like a digital signature that authorizes an app to proceed with its operations further.


Data transfer between APIs, client, and server
Data transfer often occurs in JSON format (which exists as a string) as it does not burden the network in any way due to its low memory demand. Though this string needs to be converted into a native JavaScript object if you want to access the data (more on this later). This helps faster and efficient data transfer between these parties.

Restructuring input data from the user (JSON schema)
JSON Schema is a standard format for declaring the structure of JSON data.
Validators exist to verify if a JSON document fits within schema’s constraints, i.e. the values of properties (of a data object) are valid or not. So a user’s input to a certain application is restructured to an organized JSON data with the help of this schema.
Why JSON?
While handling data (in databases) data structuring is very crucial; because it makes data querying more specific and easier.
JSON is a minimal, readable format for this structured data. It is extremely lightweight and thus is used in the interaction between server and client (HTTP requests). JSON is an alternative to XML, the latter being more complex. Using JSON, data can be managed and handled logically. The extension of a JSON file is .json .
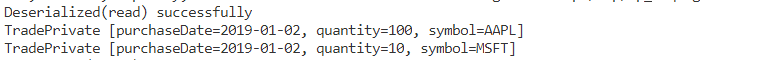
JSON vs XML
XML or Extensible Markup Language defines a set of rules for encoding documents in a format, that is both human-readable and machine-readable.
XML was the old alternative to JSON, especially in the case of web services responses. Here are some of the key differences between JSON and XML:

By now you would have understood that JSON is used to transfer data, specifically between client and server. Let's understand this a bit more in detail.
JSON is often used with AJAX (Asynchronous JavaScript and XML).
Now, what is AJAX?
Data transfer and retrieval can be achieved between web applications and the server asynchronously as per the AJAX web model without disturbing the display characteristics of the current page. In other words, refreshing the browser every time is not essential for data transfer. AJAX used a combination of tools to get this done.
Blog bonus: Build these cool web applications and showcase practical skills in your resume!
So far so good?
Think you've understood the concept of JSON so far? Take a break and test your understanding with a fun quiz to know where you stand.
Go To Quiz!JSON syntaxes and data types
The rules of writing JSON data are homogeneous to JavaScript Object Literals.
Briefly, they are as follows:
- All JSON data is written inside curly braces
- JSON data is represented as key-value pairs
- Key should always be enclosed in double quotes
- Always separate Key and value with a colon (:)
- Values should be written appropriately; for String double quotes should be used while for Numbers, Boolean quotes should not be used.
- To separate data commas (,) should be used
- For array square brackets and objects, curly braces should be used
Have a look at the following example to understand what the rules above imply:

JSON data is not too flexible with these rules. A slight violation of these rules can break your code. Make sure you validate your JSON data using any online JSON validators out there.
JSON utilizes objects or arrays (as shown in the above example) to present its data. These data contain values (of keys) which can be of the following formats -
- Number (integer or decimal)
- String (should be in double quotes)
- Boolean (i.e. true or false)
- Null
- Objects
- Arrays
An object is a collection of key-value pairs defining a data set; while an array is an ordered list of values. JSON objects can contain multiple JSON arrays and vice-versa.
JSON array declaration
[
"Full stack track", "Backend track", "Fellowship program"
]JSON object declaration
{
"id": 54d56a2c4,
"Name":"Crio.Do",
"Contact":"ping@criodo.com",
"careerPrograms": ["Crio Launch", "Crio Accelerate"]
}Following the above indentation while writing JSON is not mandatory, but this makes it more readable, don't you think?
Fun fact
You are free to space out your key-value pairs as you wish since JSON ignores whitespaces between its elements.
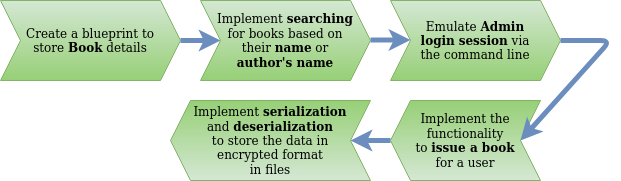
Working of JSON
Now you may be wondering about the “complex” mechanism JSON uses to transfer this data. Turns out, the process is not so complex. Rather it uses a computing method called Serialization.
Build a Library Management System to get hands-on with Serialization
Consider an application operating on a certain physical machine. If it wants to send some data to another application within the same machine or a different one it can transmit the data using some suitable network protocol. But here’s the catch. Data cannot be sent as it is, i.e. as one large chunk of data that a low-level machine can’t understand. For the two machines to understand the data, it needs to be in the form of bits i.e. 0s and 1s.
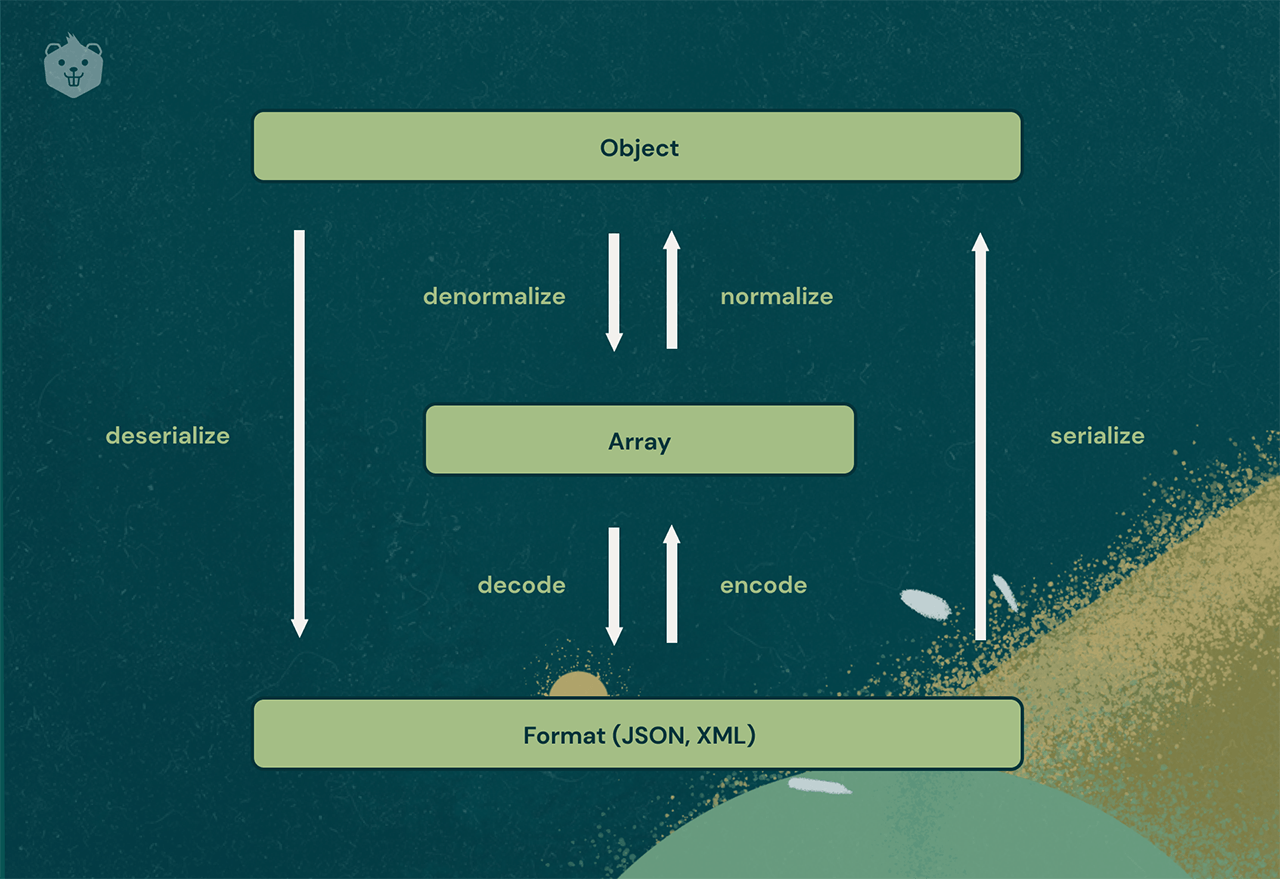
So in other words, data transfer should occur in the form of bits/bytes. This is what Serialization does.
Serialization is a mechanism that converts the state of a data object into a string of bits called a byte stream (or byte string). And once the other machine receives this byte stream it needs to "deserialize" the byte stream back to its original data object state so that it can be comfortably used further.
Deep dive into annotations for JSON parsing with fun learn by doing activities. Check it out →
This mechanism of serialization-deregulation ensures the persistence of data objects across the various applications involved.
JSON format encodes objects in a string. However, during data transmission or storage in a file, the data has to be byte strings. This isn't the usual format of complex objects.
Serialization converts these complex objects into byte strings for such use. This is the working mechanism of JSON.
The advantage of this method is that it hardly consumes much memory and thus makes JSON a lightweight tool (as mentioned before) and ideal for data transfer.
So, who exactly does this serialization-deserialization? It is the programming language you use that takes care of this process.
Take on this fun project to strengthen your understanding about Serialization-Deserialization
Fun fact
Most of the popular languages today have built-in or library support for JSON/XML; such as the latest JavaScript version (i.e. since ECMAScript 5.1) supports JSON object and their methods.
Also Go natively supports unmarshalling/marshalling of JSON/XML data.

JSON and REST APIs
An API (Application Programming Interface) is an application dedicated to transferring data between multiple software applications or even hardware software.
But the issue is APIs aren’t readable or self-expressible. API data is for machines to format and execute.
Data in APIs are commonly transferred in the JSON format because “It is easy for humans to read and write” and “It is easy for machines to parse and generate.”
Earlier it was a cumbersome task to manage and locate data of different APIs of the same parent application.
REST (Representational State Transfer) is a guiding principle for how to use URLs and HTTP protocols to format your API.
Master REST and HTTP in the upcoming free learning batch - Know More →
The table below is from the Ruby on Rails documentation, and it perfectly demonstrates how your app’s URL endpoints should be associated with its HTTP protocols. This ensures clarity in the data transfer occurs.
The following format indicates how the data is routed in your API and consequently makes it easier for others applications to understand the API.
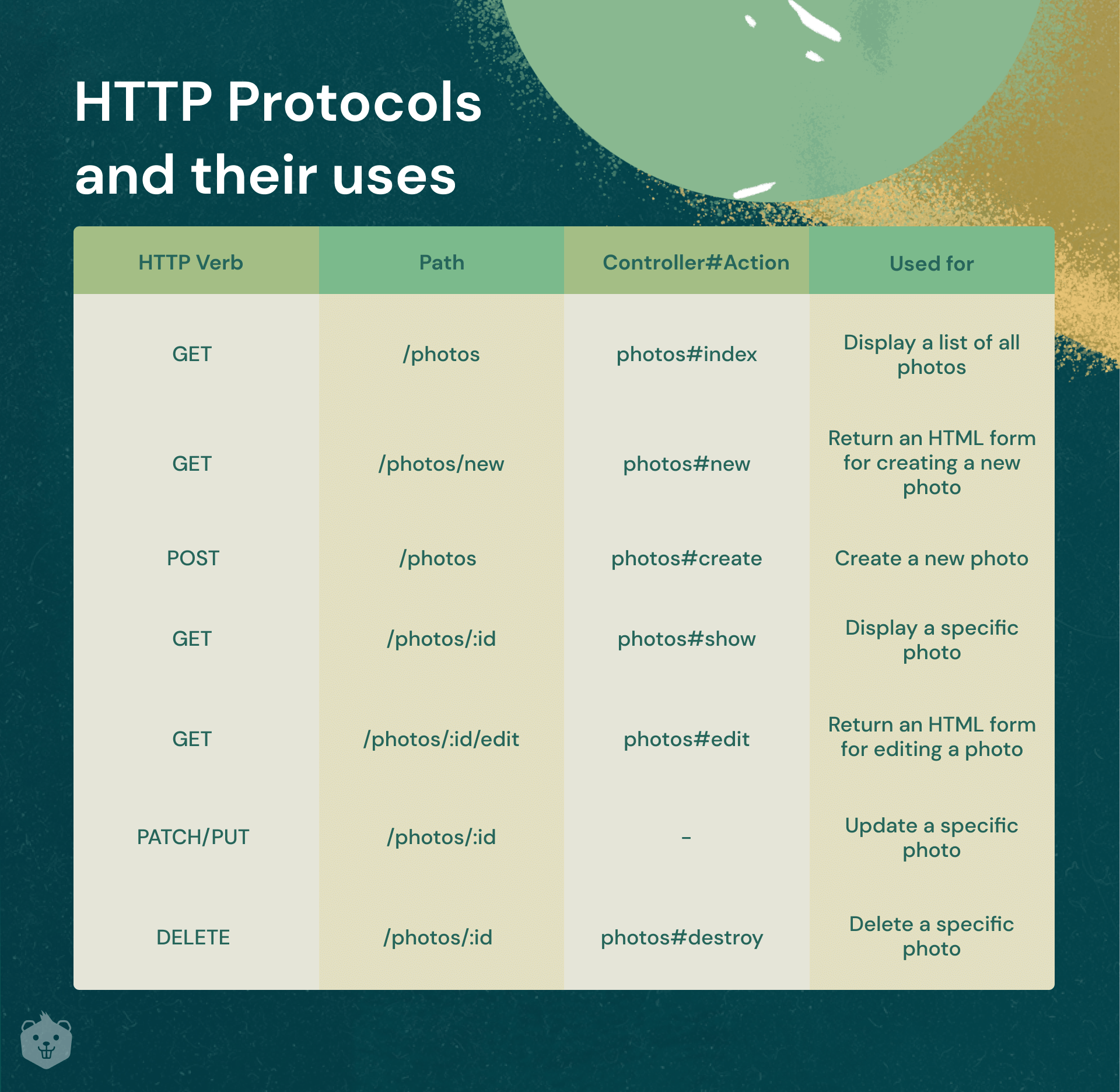
Now have a look at how the response of one such HTTP protocol looks like; observe the JSON response. This is how we as developers get to understand the data transfer occurring and thus JSON plays a crucial role in being the language here.
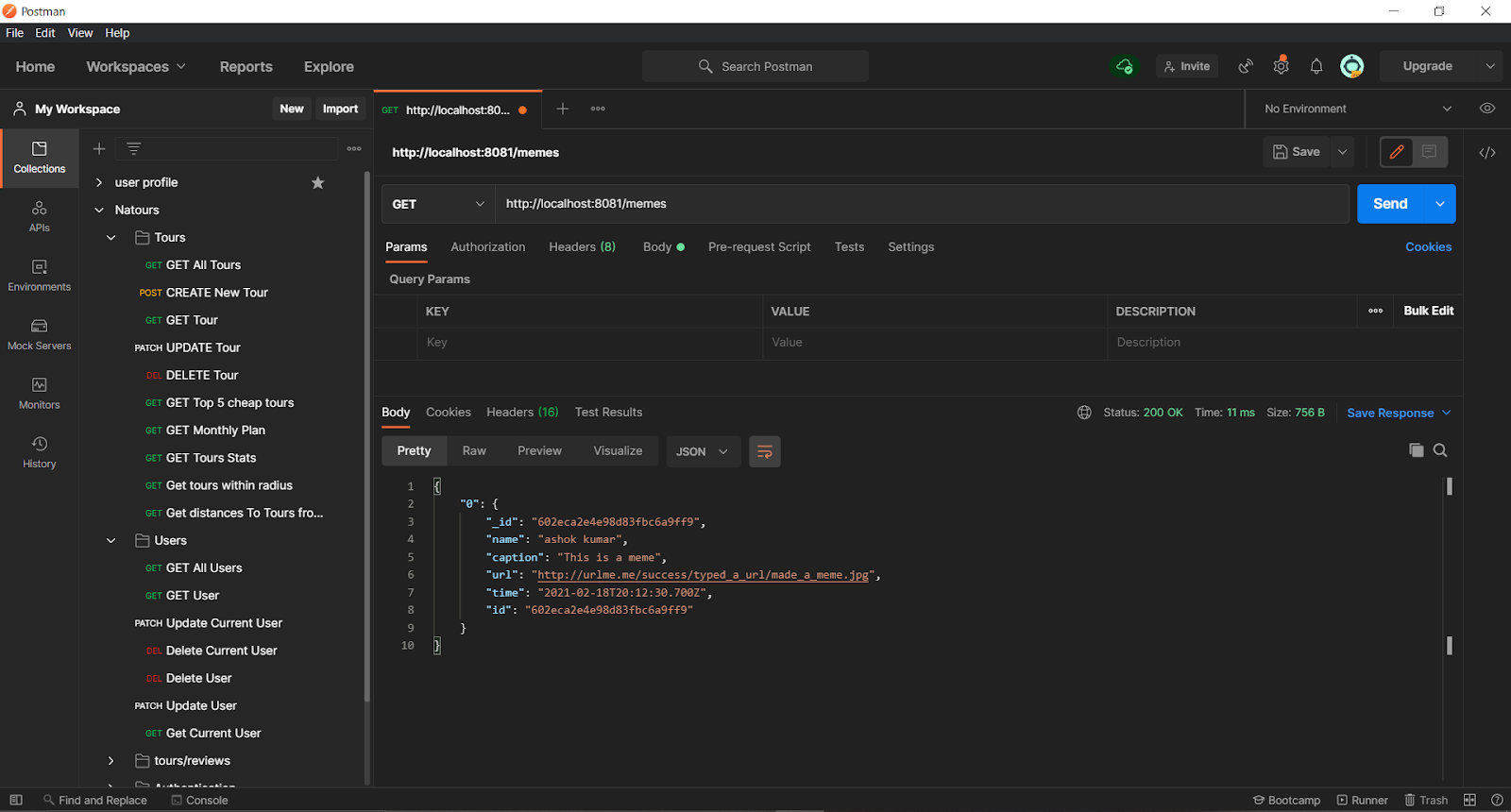
The fundamental operations that can be done on any data storage are CRUD i.e. Create-Read-Update-Delete.

Relevant HTTP protocols are used for each operation, such as for reading the data we can use GET HTTP protocol, for injecting new datasets we can use POST requests, and so on.
JSON and JavaScript
JSON is used for parsing and generating strings. This is done using the methods available in the programming language being used.


Fun fact
Did you know that JSON is also used within JavaScript code at times?
You may have seen them but not realized it then. They are declared as a variable, for instance -
let company = {
name:"Crio.Do",
type:”EdTech”,
address:{
flat:"175 & 176, Bannerghatta Main Rd, Dollars Colony",
city: "Bengaluru",
country: "India"
},
programs:["Backend Developer Track", "Full-Stack Developer Track"],
}And then you can access the contents of this JSON data simply using dot notation.
company.name // Crio.Do
company.address.city // Bengaluru
company.programs[0] // Backend Developer TrackNOTE: Dot notation (in JavaScript) allows you to see the property of the host object. You should use console.log(person.name) [for example here] to see your output in the console.
Parsing and generating are done using simple methods. Like in JavaScript you use JSON.parse() and JSON.stringify(). Let’s use ‘Adam’s’ life info to get an understanding of these methods.
NOTE: JSON is purely a string data format and it offers no methods of its own. Programming languages like JavaScript, Python, C++, Java, etc. have developed methods to handle JSON data format.
JSON.stringify()
Convert the JavaScript variable “company” into a simple string by completing the following JavaScript code snippet and compare our output with the one provided.
let company = {
"name":"Crio.Do",
"type":"EdTech",
"address":{
flat:"175 & 176, Bannerghatta Main Rd, Dollars Colony",
city: "Bengaluru",
country: "India"
},
"programs":["Backend Developer Track", "Full-Stack Developer Track"],
}
const string = //Convert the above JSON object into a string
console.log(string); //Check your outputExpected Output:
{"name":"Crio.Do","type":"EdTech","address":{"flat":"175 & 176, Bannerghatta Main Rd, Dollars Colony","city":"Bengaluru","country":"India"},"programs":["Backend Developer Track","Full-Stack Developer Track"]}JSON.stringify() method converts a given JSON object into a string. But what is the need to do this? Strings are lightweight and easier in data transportation between client and server and thus contributing to the main advantage of JSON.
JSON.parse()
let company = //convert your string back into your JSON objectThis is to convert a string back into JSON object format and thus allow us to use dot notation to access its properties.
Also, find out what other methods are available to execute these tasks and further on.
Brainstorming zone
Why am I using ‘let’ to initialize the variable, and why not var or const?
Well, for starters we should follow ES6 and stick to ‘let’ and ‘const’.
And I have used ‘let’ just to remind you guys that this way you can update the values of the properties using dot notation as ‘let’ variables let you update their values.
Think about it yourself and see if I am right? Or feel free to drop your thoughts in the comment section at the end of this blog!
There are other public instance methods like generate, fast_generate, dump, pretty_generate, load, etc. that are used with JSON for special tasks.
Are you ready to get a full score in the Basics of JSON quiz?
Get My JSON score!Practical applications of JSON
- Perhaps the most common one, JSON is used in NoSQL databases i.e. non-relational databases. These document-based databases store data in the form of queries that are converted from the accepted JSON documents. These databases accept any JSON-based documents due to the flexible nature of JSON. These databases are commonly used in web APIs and other client-server applications in general.
- A simple example of where JSON is most useful. Consider a shopping website like Amazon or Flipkart. Each product listed on their website has some parameters like name, cost, product id, and much more. These websites are dynamic in nature and hard coding each product into the database is just impossible. So what they do is they simply keep updating a JSON template file that has these parameters preset for all products. This way the system is not burdened and operations run smoothly. This is a very simple idea of how JSON can be used.
Final Thoughts
JSON has its own pros and cons when it comes to practical applications. But JSON surely has revolutionized the software industry in its own way. It is a direct subset of JavaScript so it has its own developer fanbase, lol. But on a serious note, JSON is a beautiful and critical concept. I hope this blog has given you a clear idea of what JSON is all about. Learn more about JSON by building your own APIs!
Further Learning
Understand serialization & deserialization of JSON using Jackson
Don’t miss out
Free List of 20+ Unique Web Development Projects to add to your resume.
What you’ll find inside:
Projects in Python, Java, Machine Learning. Learn skills like
- REST API
- HTTP
- Selenium
- Spring
- Bot building
- Jackson
- Serialization-Deserialization
- Firebase
- Android basics
- Game Development
And more...
Build your favorite projects by following the step-by-step instructions.
Download ProjectsTest your skills
Think you've understood JSON well? Take this short quiz and check your score now!
Start Quiz!








